
作者:量化投资学
题图:量化投资学微信公众号
在上一节《量化系统简介》中介绍了一个完整的量化投资系统包括哪些模块,本节以可转债的低转股溢价率轮动策略为例,编写一个量化回测框架,让大家对量化系统有一个直观的了解。虽然是一个简单的回测框架,但篇幅还是比较多的,因此分成两篇文章来写,第一篇为策略的实现,第二篇为策略的评价和改进。
01
策略设计
转股溢价率 = (可转债价格 - 转股价值) ÷ 转股价值
低转股溢价率轮动策略就是定期轮动买入转股溢价率最低的若干只可转债。
2. 标的池:全部可转债。
3. 回测期间:由于2018年之前可转债发行的数量很少,为避免样本量太少导致的误差,回测期间设置为2018年1月1日至2023年6月30日。
4. 择券方法:选取标的池中转股溢价率最小的20只可转债。
5. 调仓间隔:每月调仓一次,月末最后一个交易日按收盘价调仓。
6. 轮动方法:满仓轮动,在月末选取符合条件的20只可转债作为本月的持仓股,每只可转债都分配相同的金额,卖出不在持仓范围内的可转债,买入新入选持仓的可转债。
7. 交易费用和滑点:按双边千分之一作为综合的交易费率和滑点。
下面用Python来实现这个策略。本例需要事先部署好本地的Python环境并安装了akshare、empyrical、quantstats这几个库,具体做法请参照《本地Python环境部署》。本文中的代码示例在 Jupyter Notebook 中运行,当然你也可以用别的Python编辑器。
02
导入相关的库
本例需要用到numpy、pandas、akshare、empyrical、quantstats这几个库:
# 导入需要的库
import numpy as np
import pandas as pd
import akshare as ak
import empyrical as ep
import quantstats as qs03
获取可转债的相关数据
我们需要获取全部可转债的收盘价和转股溢价率。
1. 用AKShare的bond_zh_cov()接口获取可转债代码列表:
# 获取可转债代码列表
conbon_list = ak.bond_zh_cov()['债券代码'].tolist()2. 用bond_zh_cov_value_analysis()接口获取可转债的收盘价和转股溢价率,由于AKShare不支持批量获取可转债数据,我们需要一只一只可转债来获取。另外,为了防止数据获取出错,我们设置了如遇出错重试3次。获取数据的时间有点长,需要耐心等待:
# 获取可转债收盘价和转股溢价率
data_list = [] # 用于存放每只可转债的数据
i = 0
for code in conbon_list:
j = 1
while True:
try:
data = ak.bond_zh_cov_value_analysis(symbol=code) # 逐个获取可转债数据
data['转债代码'] = code
data_list.append(data) # 将每只可转债的数据添加到data_list
break
except: # 如遇出错则重试3次
j += 1
if j > 3:
break
i += 1
print("
已获取[{}/{}]只可转债的数据".format(i, len(conbon_list)), end="") # 输出处理进度3. 将所有可转债的行情数据合并为一个DataFrame:
data_df = pd.concat(data_list) # 合并DataFrame至此可转债的数据获取完毕,我们可以用 print(data_df) 将data_df输出,检查一下data_df的内容是否正确:

data_df为 DataFrame 格式,DataFrame是一个由行和列组成的二维结构的表格,与Excel中的电子表格类似。
04
数据预处理
在进行策略回测之前,需要对数据进行一些处理,使其符合要求。
1. 将日期设为datetime格式:
data_df['日期'] = pd.to_datetime(data_df['日期'])2. 删除收盘价和转股溢价率缺失的数据行:
data_df = data_df.dropna(subset=['收盘价', '转股溢价率'])3. 选取指定时间范围的数据:
start_date = pd.to_datetime('20171229') # 数据开始日期
end_date = pd.to_datetime('20230630') # 数据结束日期
data_df = data_df[(data_df['日期']>=start_date) & (data_df['日期']<=end_date)]4. 按 '转债代码' 和 '日期' 进行排序:
data_df = data_df.sort_values(by=['转债代码','日期'])5. 由于我们是按月调仓,因此按月进行时间重新采样聚合,将日线数据重新整合为月线数据:
# 设置时间重采样聚合时的取值规则
agg_dict = {
'收盘价': 'last', # 月末按收盘价调仓,因此收盘价取月末值
'转股溢价率': 'last', # 根据月末的转股溢价率调仓,因此转股溢价率取月末值
}
data_df = data_df.set_index('日期') # 将'日期'设为dataframe的索引
resample_df = data_df.groupby('转债代码').apply(lambda x: x.resample('1M').agg(agg_dict)) # 按“月”对数据进行重新采样聚合
resample_df = resample_df.reset_index() # 重置索引上述代码用groupby函数按转债代码进行分组;然后在每个分组内用resample函数进行时间聚合,resample('1M')表示聚合为月度数据;agg函数用于规定聚合的规则,在本例中我们对'收盘价'和'转股溢价率'这两列进行聚合,都是取月末最后一日的值为聚合后的值。
数据处理完后,我们用 print(resample_df) 命令将数据输出,观察处理后的数据:
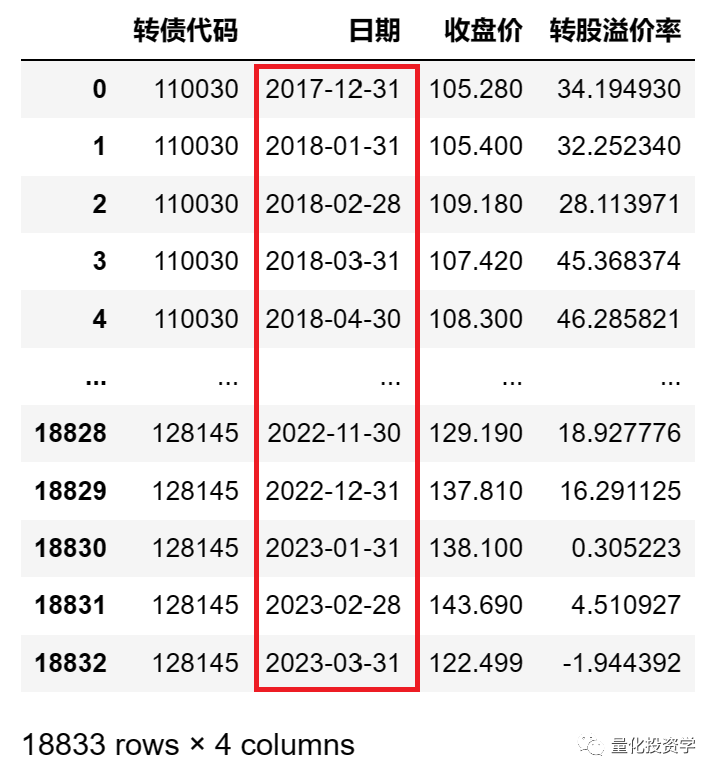
可以看到,原来的日频数据已经转换为月度数据。
05
执行选股(择券)并计算净值曲线
1. 计算月度收益率,并用0值来填充缺失值:
resample_df['月收益率'] = resample_df.groupby('转债代码')['收盘价'].pct_change().fillna(0)上述代码先用groupby函数按转债代码进行分组,然后用pct_change函数计算收益率,用fillna函数来填充缺失值。
2. 计算转股溢价率排名:
resample_df['转股溢价率排名'] = resample_df.groupby('日期')['转股溢价率'].rank(ascending=True)上述代码先用groupby函数按日期进行分组,然后在每个日期用rank函数计算当日的排名。
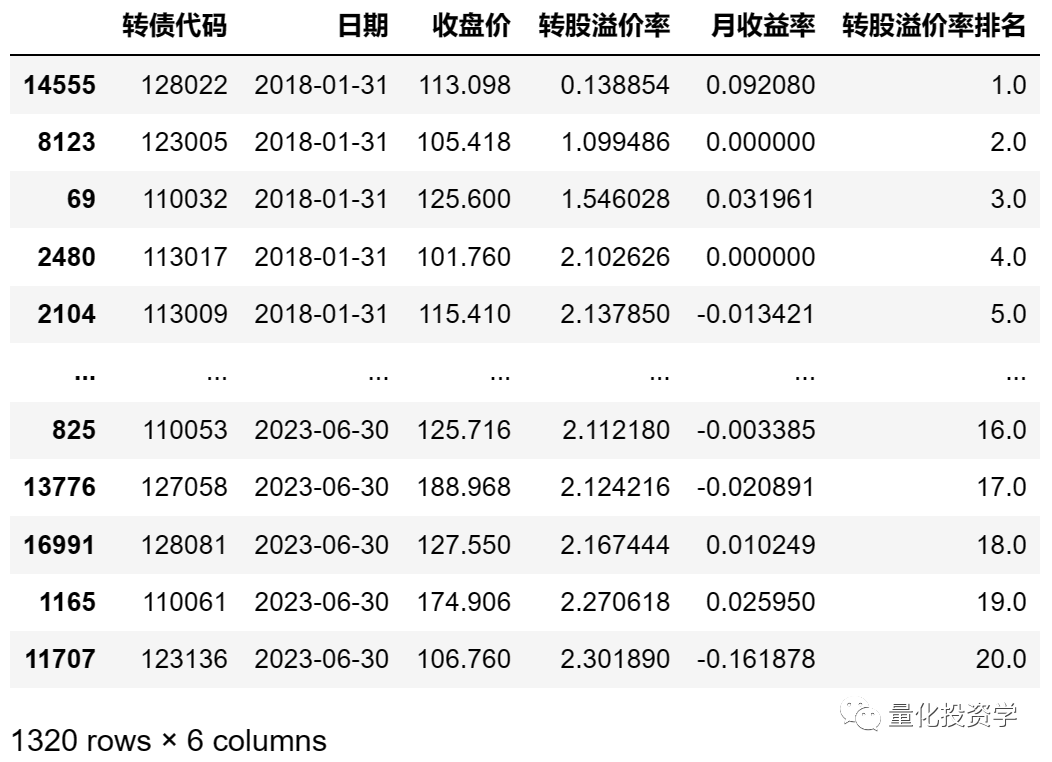
3. 选择转股溢价率排名在20名以内的作为持仓的可转债:
hold_df = resample_df[resample_df['转股溢价率排名'] <= 20]至此我们完成了择券的工作,可以用 print(hold_df) 将选出的可转债打印出来观察:
4. 计算每只可转债扣除交易成本后的收益率(注意买入和卖出均需扣除交易成本):
# 计算扣除交易成本后的月收益率
c_rate = 1/1000 # 交易费率
hold_df['月收益率'] = - c_rate + (1 + hold_df['月收益率']) * (1 - c_rate) - 15. 计算这一个月中所有持仓转债的综合收益率,因为每只可转债都分配相同的金额,因此持仓收益率就是每只可转债收益率的平均值:
# 计算持仓可转债的综合收益率
results_df = hold_df.groupby('日期')[['月收益率']].mean()上述代码先用groupby函数按日期分组,然后用mean函数计算当日的平均值。
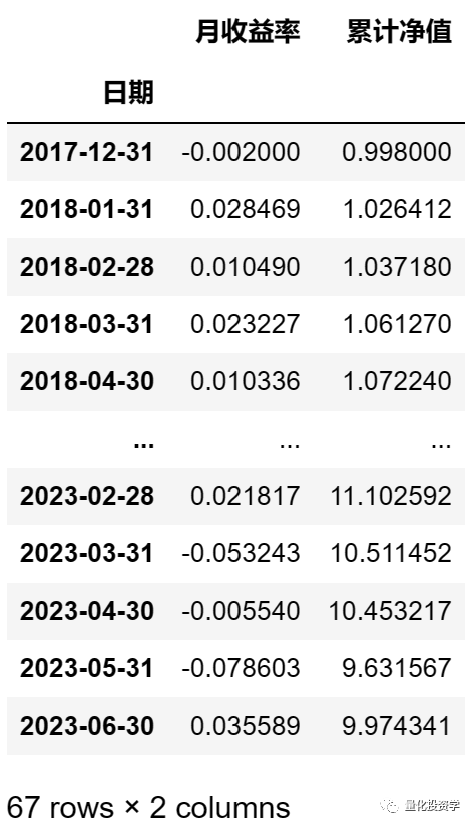
6. 最后,通过持仓可转债每月的综合收益率就能计算持仓的累计净值了:
results_df['累计净值'] = (results_df['月收益率'] + 1).cumprod() # cumprod()为连乘函数我们用 print(results_df) 将回测结果打印出来观察:
06
添加用于比较的基准数据
基准数据可以用来跟策略对比,对比的结果是评价策略好坏的重要依据。集思录可转债等权指数是集思录编制的等权持有全部可转债的指数,我们以集思录可转债等权指数作为基准,跟我们的策略进行对比。
1. 用AKShare的bond_cb_index_jsl()接口获取可转债等权指数的数据,将日期的格式设置为datetime格式,并将日期这一列设为索引:
# 获取可转债等权指数的数据
bench_mark = ak.bond_cb_index_jsl()[['price_dt', 'price']]
bench_mark['price_dt'] = pd.to_datetime(bench_mark['price_dt']) # 将日期设为datetime格式
bench_mark = bench_mark.set_index('price_dt') # 将日期设置为索引2. 将可转债等权指数按月进行重采样聚合后,添加到results_df数据表中:
results_df['基准_可转债等权指数'] = bench_mark.resample('1M').agg({'price':'last'})/bench_mark['price'][0]在上述代码中,将可转债等权指数按月进行重采样聚合后还除以基准指数的第一个值bench_mark['price'][0],这样做的目的是将基准指数的初始值设为1,以便于和策略的净值曲线进行比较。
3. 计算可转债等权指数的月收益率:
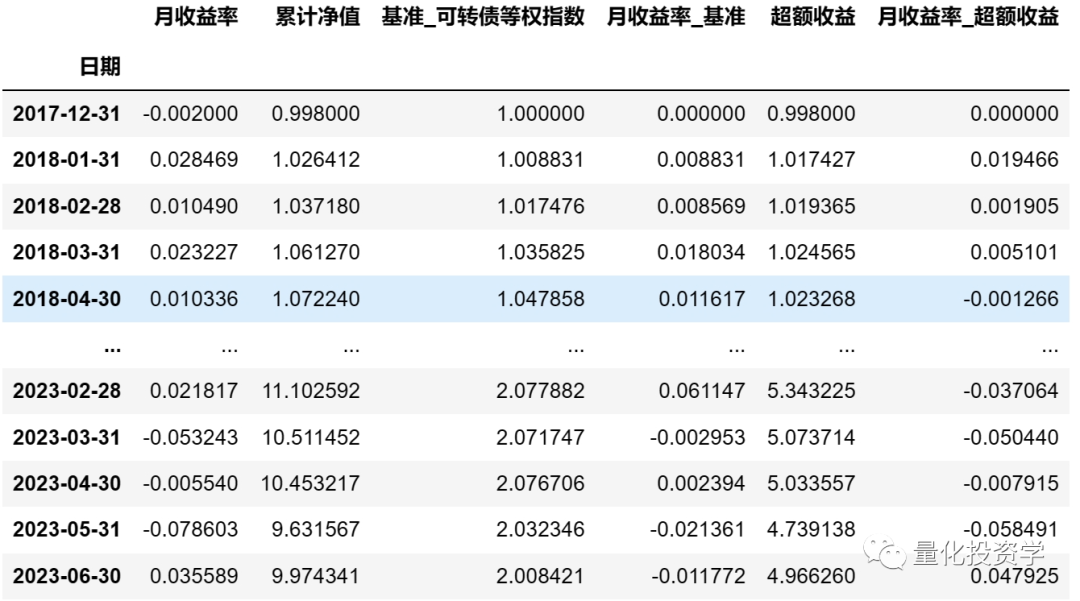
results_df['月收益率_基准'] = results_df['基准_可转债等权指数'].pct_change().fillna(0)4. 计算策略净值相对于可转债等权指数的超额收益和超额收益的月变动率:
results_df['超额收益'] = results_df['累计净值'] / results_df['基准_可转债等权指数']
results_df['月收益率_超额收益'] = results_df['超额收益'].pct_change().fillna(0)计算完后用 print(results_df) 查看一下数据:
这样就完成了策略回测的计算,我们做个总结,本文的回测代码主要包括以下几个步骤:
1. 获取数据,并对数据进行预处理;
2. 根据选股规则选出持仓股票;
3. 根据持仓股票计算收益率和净值曲线。
在下节内容中,我们接着介绍策略的评价、可视化分析和回测框架的改进等内容。
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
