
作者:川总写量化
题图:川总写量化微信公众号
摘要
实证资产定价中,多重假设检验容易造成样本内的伪发现。本文带你了解多重假设检验的源起,中兴和未来。
1 源起
多重假设检验(multiple hypothesis testing)指的是同时检验多个原假设。在实证资产定价中,使用历史数据挖掘成百上千个因子正是多重假设检验。当同时检验多个假设时,运气成分(噪声)会导致单个原假设检验结果的显著性被高估。当排除了运气成分后,原假设可能不再显著。
在单一假设检验中,通常以 0.05 作为 p-value 的阈值来判断是否接受原假设,其对应的 t-statistic 为 2.0。这也早已成为实证资产定价中挖因子的依据。然而多重假设检验的存在使得低 p-value 无法准确说明因子是否有效。假设我们同时检验 100 个独立的因子并发现某个因子的 t-statistic = 2.0。在这种情况下,我们不能说该因子在 0.05 的显著性水平下显著。这是因为哪怕这 100 个原假设都为真(即它们的超额收益都为零),那么仅仅靠运气,其中出现 t-statistic 大于 2.0 的概率高达 99%。如果仍然按照传统意义上的 2.0 作为 t-statistic 的阈值来评价因子是否显著,注定会有很多伪发现(false discoveries 或 false rejections),即第 I 类错误。因此,正确处理多重假设检验的影响成为实证资产定价的关键。
在这方面,学术界的研究成果可以被划分为两大类,即频率主义方法和贝叶斯方法。为了排除运气(噪声)的影响,频率主义方法以控制第 I 类错误为目标,通过增大标准误(standard errors)来修正单个因子的显著性水平。直觉上说,增大标准误意味着增大置信区间,因而这使得单个检验的显著性门槛更加严格:只有当一个因子原始的 t-statistic (远)超过传统意义上的 2.0 水平,其才有可能在被修正后依然显著。
早期的方法多属于频率主义方法,目标是控制第 I 类错误。在统计学中,族错误率(family-wise error rate,简称 FWER)、伪发现率(false discovery rate,简称 FDR)以及伪发现比例(false discovery proportion,简称 FDP)是常见的第 I 类错误指标。让我借助下表来解释它们。


近年来,还有一些以控制族错误率为目标的算法被提出,包括 White (2000) 的 bootstrap reality check 方法和 Romano and Wolf (2005, 2007) 的 StepM、k-StepM 方法等。这三种算法均通过自助法(bootstrap)对因子收益率数据进行重采样,并在此基础上结合正交化求出 t-statistic 的阈值,因而无需对数据的分布做任何假设。
在上述描述中,正交化和自助法两个词反映了这些算法以及频率主义方法的核心。正交化的作用是消除因子在样本内的收益率均值,使因子收益率在时序上成为均值为零的随机扰动;自助法的作用是通过对正交化后的收益率进行采样从而得到仅靠运气成分而造成的检验统计量的分布,以此就可以判断原始因子的显著性是真实的还是仅仅是噪声造成的。值得一提的是,由于太过严苛,以控制族错误率为目标并不是很适合金融领域。

2 中兴
近年来,学术界越来越重视多重假设检验问题对因子显著性的影响,在这方面也诞生了很多优秀的研究成果。在介绍这些研究成果之前,让我们先来简要回顾一下相关的背景。
2017 年,时任美国金融协会(AFA)主席 Campbell Harvey 教授在年会上以 The Scientific Outlook in Financial Economics 为题进行了主席演讲。以一个学者应有的科学态度和操守,Harvey 教授深刻剖析了近年来学术界在实证资产定价研究中的一个错误趋势。为了竞逐在顶级期刊上发表文章,学者们通过各种数据窥探手段过度追求因子的低 p-value(即 p-hacking)。由于有意或无意的数据操纵、使用不严谨的统计检验手段、错误地理解 p-value 的含义、以及忽视因子的内在经济学逻辑,很多在功利心驱使下被创造出来的因子在实际投资中根本站不住脚(McLean and Pontiff 2016)。此外,发源于因子投资、在业界早已成为主流的 Smart Beta ETF 基金也饱受 p-hacking 问题困扰。Huang, Song and Xiang (forthcoming) 记录了这类基金被推出后其表现相较于其样本内表现急剧下滑的实证发现,并指出过度的数据挖掘是这背后的罪魁祸首。
要论为学术界敲响多重假设检验警钟的代表性论文,Harvey, Liu and Zhu (2016) 当仁不让。该文研究了学术界发表的 316 个因子。以控制伪发现率为目标,该文发现只有一个因子原始 t-statistic 超过 3.0 时,其才在排除多重假设检验的影响后依然是有效的。除此之外,该文指出在全部三百多个因子中,伪发现的比例高达 27%。
在试图消除多重假设检验的影响时,除了选择合适的统计手段外,另一个必须面对的问题是到底有多少个原假设被同时检验(即有多少因子被挖出)。这个问题之所以重要,是因为基数决定了运气的多寡。比如,检验 100 个和 10000 个因子相比,万里挑一的肯定要比百里挑一的更显著。所以,只有知道学术界到底挖了多少因子,才有可能准确修正多重假设检验问题。
看到这里,有的读者可能会问,Harvey, Liu and Zhu (2016) 考虑了 300 多个因子、Hou, Xue and Zhang (2020) 复现了 450 个左右因子,它们是否就是学术界挖掘的全部呢?不幸的是,答案是否定的。因为这些仅仅是被发表出来的因子,而学术界在这背后到底尝试了额外多少因子是无从而知的。由于已发表的因子是所有被研究因子的子集,因此我们可以判断 Harvey, Liu and Zhu (2016) 发现的 3.0 阈值仅仅是保守估计。幸运的是,Chordia, Goyal and Saretto (2020) 创造性使用模拟推断出基于研究的因子集的统计特征如何消除多重假设检验的影响。该文将 t-statistic 的阈值进一步提升至 3.4 以上,且模拟计算显示,伪发现比例高达 45.3%。
频率主义方法依赖于引入衡量评价多个假设整体第 I 类错误的指标(例如族错误率或伪发现率),并以此为目标调整单一假设检验的显著性。与频率主义方法相对应的,是贝叶斯方法。贝叶斯方法允许人们引入从经济学理论得出的关于因子是否为真的先验。但缺点是完整的贝叶斯框架计算十分复杂,因此人们有时不得不做出一些妥协和简化。
Scott and Berger (2006) 在贝叶斯框架下提出了研究因子收益率的一个三层模型。利用该模型,人们可以计算出每个因子为真的后验概率。随着同时检验的假设个数(即因子个数)的增加,后验概率将更加接近 0。换句话说,随着噪声信号(虚假因子)个数的增多,真实因子传递出来的证据也会随之而降低,这体现出和频率主义方法相对应的对多重假设检验的惩罚。这正是贝叶斯框架自带奥卡姆剃刀效应,即根据同时被检验的因子的个数自动调整因子为真的后验概率的原因。
虽然完整的贝叶斯框架理论完整,但实操起来也有很多问题。例如它的假设(尤其条件独立性方面的假设)太过苛刻,且在计算方面,当同时考虑的因子个数很多时,计算每个因子为真的后验概率极具挑战。第三,即便得到了每个因子为真的后验概率,我们依然需要构建一个判断准则,即后验概率高于多少阈值的因子可以被视为真。然而在这方面,目前还没有太多指导。
鉴于完整贝叶斯框架的实践应用充满挑战,人们便希望退而求其次通过别的方式利用贝叶斯思想。在这方面,Harvey (2017) 提出了最小贝叶斯因子,并通过它计算贝叶斯后验 p-value 进而判断因子是否显著。为了让各位小伙伴更好地理解最小贝叶斯因子以及贝叶斯后验 p-value,先来说说 p-value 的正确含义。由定义可知,p-value 表示原假设下观测到某(极端)事件的条件概率。因此,p-value 越低,说明在原假设(因子预期收益率为零)下越不太可能出现样本数据中的平均收益率。

对于检验因子来说,后验机会比是我们真正关注的问题。它告诉我们原假设和备择假设后验概率的高低——一个特别低的后验机会比意味着原假设的后验概率很低,因此我们可以安全地拒绝原假设,即认为因子是真实的。不过,想要计算后验机会比,就必须要先算出贝叶斯因子。但从上面的定义可知,计算它时需要指定备择假设下的先验分布,但这往往非常困难。不过好消息是,在众多贝叶斯因子的取值中,有一个特殊的取值,它就是最小贝叶斯因子(minimum Bayes factor,简称 MBF)。

为了在实际操作中应用贝叶斯后验 p-value,除了需要知道最小贝叶斯因子外,还需要指定先验机会比。为此,一些经验法则为:(1)对于严重缺乏经济学依据的因子,先验机会比 49:1;(2)对于似是而非的因子,先验机会比 4:1;(3)对于具备经济学理论依据的因子,先验机会比 1:1。
3 未来
除了以上标准意义上的贝叶斯方法,近年来的另一个新的思路是对贝叶斯思想的拓展,即通过先验知识决定真实因子在所有因子中的占比,然后通过 bi-modal mean 分布对真实和虚假因子的预期收益率建模。这方面的代表是 Harvey and Liu (2020, 2021)。在我看来,它们代表实证资产定价中多重假设检验的未来。

回顾一下,频率主义方法中的多重假设检验修均可以归纳到正交化和自助法这两个核心思想的综合运用。其中正交化的作用是在样本内剔除每个因子的超额收益(即把因子转变为噪声);自助法则是在正交化后的基础上通过重采样数据,以此获得仅由运气造成的因子收益率的 t-statistic 的分布。在得到该分布后,传统频率主义方法往往以控制事先约定的第 I 类错误上限(例如常见的 5%)来选定 t-statistic 的阈值,并以此确定真实因子。在传统方法中,存在两个问题:
1. 正交化过程通常会对所有因子进行(这隐含的假设是所有因子的超额收益均为零)。然而在现实中,这种处理忽视了先验的作用。对于待检验的诸多因子而言,人们可根据金融学先验认为其中一定比例的因子是真实的,然而传统方法忽视了这一信息。
2. t-statistic 阈值的确定一般是以控制第 I 类错误为唯一目标。这么做的结果是,传统多重假设检验方法的第 II 类错误率往往很高,因此功效( power=1-第 II 类错误率 ) 往往很低。举个极端的例子,如果某个算法把所有原假设都接受了,那么它也就没能发现任何真正的因子,即功效为零。
在 α 越来越稀缺的当下,第 II 类错误的成本变得越来越高,让人们愈加重视两类错误之间的取舍。尽管如此,传统方法仅关心第 I 类错误(即控制伪发现)也实在是无奈之举。这是因为哪怕对于单一假设检验,计算第 II 类错误率都并不容易,更不用说多重假设检验问题。如果想要计算第 II 类错误率,就必须知道备择假设下参数的取值。但显然,对于成百上千个因子来说,遍历它们备择假设下的预期超额收益率不切实际。这个巨大的障碍使得人们难以将单一检验中计算第 II 类错误率的方法复制到多重假设检验问题中。

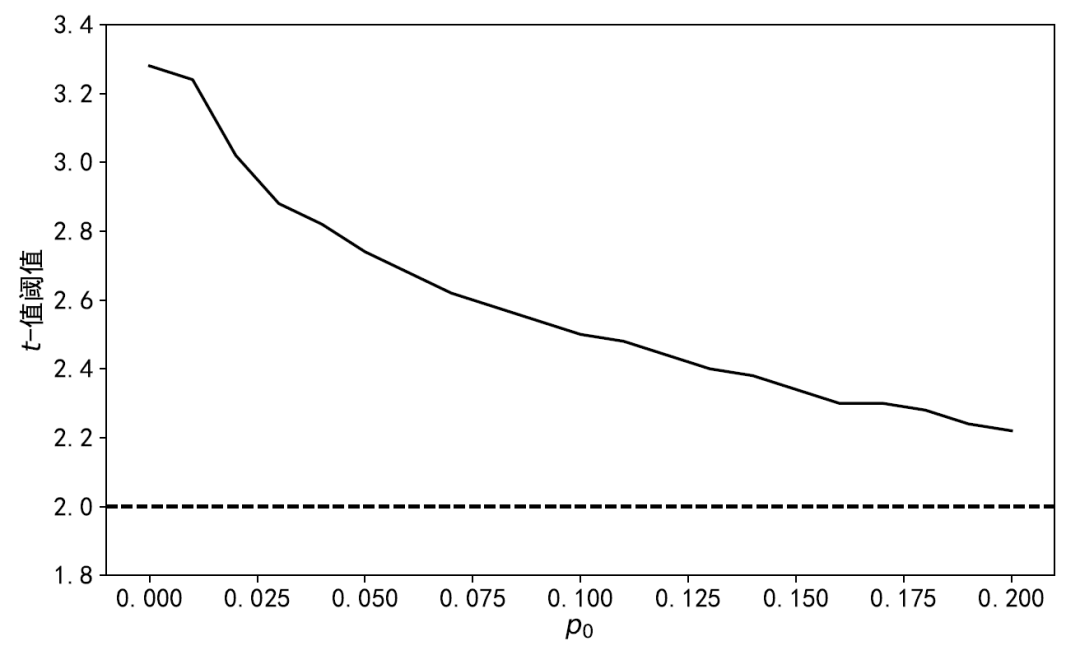
近年来,Harvey 教授和他的长期合作者刘岩教授(对,Harvey and Liu 里面的 Liu!)一直致力于呼吁学术界抵制追逐超低 p-value 的不良学术风气。两位的诸多实证结果不仅质疑了过去几十年来学术研究中挖掘出的相当一部分因子,更是从某种程度上挑战了学术研究的权威。然而,出于对学术风气和学术成果的保护,站在他们对立面的质疑之声也同样此起彼伏。这其中首当其冲的要数 Chen (2021) 和 Jensen, Kelly and Pedersen (2023)。
Chen (2021) 通过思想实验指出仅靠 p-hacking 根本无法解释学术界发现的诸多非常显著的因子,并通过他的模型得出了一系列推论,间接指出对于 p-hacking 的担忧可能被夸大了。然而,无论是学术界还是业界,大家的共识是所有因子预期收益联合为零(即前文提到的 ensemble null 先验)这个原假设一定会被拒绝,即人们都认可存在一部分显著因子。因此,根本没有人否认仅靠 p-hacking 无法解释一些非常显著的真实因子被发现。但是人们也同样相信,多重假设检验和发表偏差的影响促使一些虚假因子的诞生。所以,在所有因子中,到底有多少是真实的?更进一步,对于通过多重假设检验修正的真实因子,它们的收益率在样本外的收缩系数又是多少?然而 Chen (2021) 并没有回答这些问题。
面对质疑,Harvey and Liu (2021) 做出了回应。在检验因子时,除去被发表的之外,还需要考虑因为不够显著而被学者们放弃的因子,这些构成了总共被尝试的因子。但现实中,总共尝试的因子个数是未知的。为了解决这个难题,Harvey and Liu (2021) 再次对因子预期收益率使用了 bi-modal mean 先验分布,并通过理论模型和参数校准回答了关键问题。
参数校准的结果或许让人有些意想不到(但细想其实是合理的),即这个问题本身是未识别的(lack of identification)。换句话说,它的最优参数不唯一。在三组参数下,模拟得到的统计指标均和实际值较好地吻合。而这个问题之所以是未识别的,原因恰恰是人们观察到的只有被发表的因子,而学术界到底尝试了多少个因子永远是未知的。这是在研究 p-hacking 问题时注定无法逃避的现实。至于它可能的取值范围则取决于研究者的经验和对实证数据的理解。

谈到多重假设检验,其他学科对它的重视其实由来已久,而金融学对它的重视则相对较晚。但好消息是,Harvey 和刘岩两位教授在这项 research agenda 上的探索,已经让人们充分意识到这个问题,并开始通过各种手段来降低 p-hacking 的影响。
由于多重假设检验的危害颇具争议性,因此学术界以开放的心态来讨论它至关重要。正如前文所述,因为人们只观测到了被发表的因子,而不知道到底尝试了多少因子,所以这个问题注定是未识别的。正因如此,对 p-hacking 的研究确实存在主观的一面。坦然承认这个计量上的系统问题,并通过合理的先验得到令人信服的结论,才是应有的研究态度。
最后,一图总结多重假设检验的源起、中兴和未来。

One More Thing
读到此处,你一定看出了我对 Harvey and Liu 的钟爱。事实上,我的《出色不如走运》系列系统化地介绍过他们两位合作的诸多研究成果。这不仅源于我对这个研究方向的关注,更是因为我对两位教授为人的钦佩。其中,刘岩老师本科毕业于清华数学系,不仅是我的校友,更是我投研路上的良师益友。
所以,从来不做广告的川总今天要硬核做广告了。刘老师去年回国加盟了清华经管(坐标深圳)。其课题组正在招收金融大模型(偏 CS 背景)和金融大数据(偏经济金融类背景)方向的博士后(见下方链接和截图)。无论是课题方向,还是刘老师的能力和为人,这都是个难得的机会,感兴趣且 qualified 的小伙伴不妨关注一下,也许下一篇出现在 [川总写量化] 里的文章就是 Liu and You (forthcoming)!
https://talent.sigs.tsinghua.edu.cn/recruit-fg/job/254/detail?from=PositionList
https://talent.sigs.tsinghua.edu.cn/recruit-fg/job/255/detail?from=PositionList



参考文献
Benjamini, Y. and Y. Hochberg (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, Series B 57(1), 289-300.
Benjamini, Y. and D. Yekutieli (2001). The control of the false discovery rate in multiple testing under dependency. Annals of Statistics 29(4), 1165-1188.
Bonferroni, C. E. (1936). Teoria Statistica Delle Classi e Calcolo Delle Probabilità. Florence, Italy: Libreria Internazionale Seeber.
Chen, A. Y. (2021). The limits of p-hacking: Some thought experiments. Journal of Finance 76(5), 2447-2480.
Chordia, T., A. Goyal, and A. Saretto (2020). Anomalies and false rejections. Review of Financial Studies 33(5), 2134-2179.
Harvey, C. R. (2017). Presidential address: The scientific outlook in financial economics. Journal of Finance 72(4), 1399-1440.
Harvey, C. R. and Y. Liu (2018). Detecting repeatable performance. Review of Financial Studies 31(7), 2499-2552.
Harvey, C. R. and Y. Liu (2020). False (and missed) discoveries in financial economics. Journal of Finance 75(5), 2503-2553.
Harvey, C. R. and Y. Liu (2021). Uncovering the iceberg from its tip: A model of publication bias and p-hacking. Duke University, Purdue University.
Harvey, C. R., Y. Liu, and A. Saretto (2020). An evaluation of alternative multiple testing methods for finance applications. Review of Asset Pricing Studies 10(2), 199-248.
Harvey, C. R., Y. Liu, and H. Zhu (2016). ... and the cross-section of expected returns. Review of Financial Studies 29(1), 5-68.
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics 6(2), 65-70.
Hou, K., C. Xue, and L. Zhang (2020). Replicating anomalies. Review of Financial Studies 33(5), 2019-2133.
Huang, S., Y. Song, and H. Xiang (forthcoming). The smart beta mirage. Journal of Financial and Quantitative Analysis.
Jensen, T. I., B. T. Kelly, and L. H. Pedersen (2023). Is there a replication crisis in finance? Journal of Finance 78(5), 2465-2518.
McLean, R.D. and J. Pontiff (2016). Does academic research destroy stock return predictability? Journal of Finance 71(1), 5-32.
Romano, J. P., A. M. Shaikh, and M. Wolf (2008). Formalized data snooping based on generalized error rates. Econometric Theory 24(2), 404-447.
Romano, J. P. and M. Wolf (2005). Stepwise multiple testing as formalized data snooping. Econometrica 73(4), 1237-1282.
Romano, J. P. and M. Wolf (2007). Control of generalized error rates in multiple testing. Annals of Statistics 35(4), 1378-1408.
Scott, J. G. and J. O. Berger (2006). An exploration of aspects of Bayesian multiple testing. Journal of Statistical Planning and Inference 136(7), 2144-2162.
White, H. (2000). A reality check for data snooping. Econometrica 68(5), 1097-1126.
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
