
中金 | 机器学习系列:如何结合树模型与深度学习的优势
作者:中金量化及ESG
题图:中金量化及ESG微信公众号
以下文章来源于中金点睛 ,作者郑文才 高思宇等中金点睛.图文并茂讲解中金深度研究报告
 聚合树模型和深度学习模型作为机器学习领域较为成熟稳定的模型类型来说在不同场景下各有其优势。本文尝试在选股任务中将两种模型的优势结合,构建兼顾稳定性、高收益与高信息增益的选股模型。我们发现双模型串行结构样本外表现较好,扣费滚动多头组合年化收益率44.1%,相对全市场等权基准超额36.9%。
聚合树模型和深度学习模型作为机器学习领域较为成熟稳定的模型类型来说在不同场景下各有其优势。本文尝试在选股任务中将两种模型的优势结合,构建兼顾稳定性、高收益与高信息增益的选股模型。我们发现双模型串行结构样本外表现较好,扣费滚动多头组合年化收益率44.1%,相对全市场等权基准超额36.9%。

Abstract
摘要
公众号内容仅为原报告节选,获得完整报告请联系相应分析师或销售
树模型VS深度学习模型
尽管近些年深度学习在图像和文本领域取得了突出成果,但学术研究发现在特定任务下基于决策树的聚合模型依然可以达到优秀表现。这主要是因为树模型在处理中小样本表格数据更为稳定,此外在训练速度、超参数调整、可解释性以及处理缺失数据上也展现出了一定优势。[1]
深度学习模型一般使用具有大量参数的神经网络结构拟合目标函数。本文采用了一种多任务编码/解码器MLP模型(Multi-task Encoder/decoder Multi-Layer Perceptron,下称MMLP),结合编码/解码器结构同时进行分类与回归的多任务同步训练。我们希望最终将两模型结合从而同时发挥各自的优势,达到1+1大于2的效果。
树模型和深度学习在选股任务中各具优势
我们使用中金量化组开发的日度价量、日内高频和基本面一共247个截面选股因子作为输入,对比树模型和深度学习模型的表现。我们发现树模型训练更灵活高效,预测长期目标任务下月度换仓表现相对更强,多头年化收益率15.5%,相对全市场等权超额10.2%。深度学习模型MMLP在短期目标预测任务中表现更好,周度换仓频率下行业与市值中性化后的扣费多头年化收益率为41.20%,相对全市场等权基准超额为32.26%。
具体来说我们发现树模型在使用基本面数据对于长期目标(20与60交易日后的目标)的预测效果和因子收益率相对MMLP模型更好,而MMLP模型在对于1-20交易日后的目标拟合效果更好,样本外表现也更佳。这也印证了我们在第一章提到的树模型对于小样本数据有比较优势的观点。一般来说深度学习模型由于具有更大参数量可以更细腻地捕捉短周期的变化,而树模型的拟合方式相对更加离散,但加入Optuna搜参框架可以帮助树模型有效改善上述情况。
树模型与深度学习模型的结合
经过上述分析我们认为如果可以结合树模型和深度学习模型各自优势或许能够使得模型性能得到进一步提升。我们尝试了两种模型结合方式: 1. 使用包含更多长期信息的基本面因子训练树模型,使用价量因子训练深度学习模型,将两种模型的信息通过并行结合;2. 将价量因子先输入深度学习模型,取深度学习模型最后的隐层编码作为特征输入到树模型中,将两模型串行连接。
结合长短期信息的并行的结合方式可以提升ICIR等表征因子稳定性的指标,而串行结构可以提升因子的多头超额收益率。最终我们发现周度换仓下双模型串联结构的费后样本外滚动多头年化收益率44.1%,相对全市场等权基准超额36.9%,信息比率达4.9,且因子相关性和现有因子库的相关性较低,具有较高信息增益。近期A股市场高波动环境下,以上两种连接结构截至2024年9月底的最近3个月样本外多头表现相对市场等权超额均为正。
Text
正文
树模型VS深度学习模型
树模型和深度学习模型是机器学习模型领域较为重要,也都是当前应用在因子挖掘、合成等任务的主流模型。树模型较为轻量化且部署简便,其参数量和算力需求相对较低,较为适合小样本数据;深度学习模型结构复杂,参数量更大,拟合程度相对更深。两种模型各自有其独特优势和适用场景。在本文的框架下,树模型代表包括XGBoost、LGBM和Random Forest三大类以树模型为弱学习器的聚合模型(下简称树模型)。深度学习模型我们选用Jane Street在Kaggle比赛中开源的结合编码器和解码器的全连接神经网络(MLP)结构。两类模型的发布时间也较为接近,方便做出对比。
灵活高效的决策树聚合模型
近些年尽管深度学习在图像和文本领域取得了显著成就,但在金融领域常见的表格数据上,基于树的模型依然表现更优。这主要是因为树模型在处理无信息特征、保持数据方向、学习不规则函数方面更为稳定。此外,树模型在训练速度、超参数调整、以及处理高基数分类特征和缺失数据上也展现出了特定优势(L.Grinsztajn,2022)。这些特性使得树模型在中等规模数据集上即使在深度学习模型经过大量超参数优化后仍然保持领先地位。另外树模型的特征高解释性方面在金融领域也是重要优势。[2]
本文使用的树模型主要有XGBoost、LGBM和Random Forest。之所以被称为树模型,是因为这些模型一般由决策树模型聚合而成的集成学习器,前两者将决策树以串行方式连接,后者将基础弱学习器以并行方式连接。同样是决策树聚合模型,三种模型各有各自的连接特点。而底层的树结构我们采用以上三种模型默认的基础决策树结构一般为CART(Classification and Regression Tree)决策树。
图表1:两种常见的树模型聚合方法
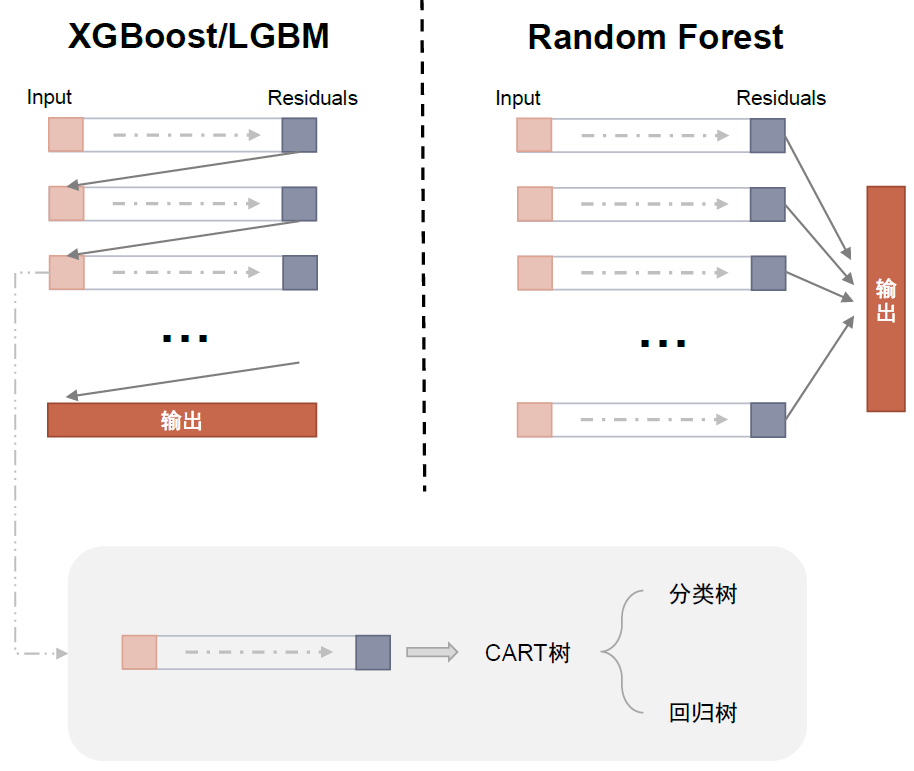
资料来源:中金公司研究部
多目标编码/解码器的混合深度学习模型:MMLP
深度学习模型具有强大的非线性拟合能力,通常能够在大规模的数据集上学习有效的数据模式及特征,并取得优于传统机器学习模型的性能表现。多层感知机作为其中较为基础的网络结构,已经在分类及预测等常规任务上得到许多成功的应用;编码-解码器(Encoder-Decoder)作为相对前沿的一类框架,目前被广泛地应用于自然语言处理、计算机视觉、语音处理等领域,在机器翻译、图像去噪等任务中发挥着重要作用。其核心思想是利用编码器对输入向量中的关键信息进行提取和整合,得到高度压缩的隐式空间特征;而后借助编码器将抽象特征解析为所需要的向量(例如重构输入数据,预测目标变量等)。
本文由Jane Street在Kaggle比赛中开源的方案为启发,将上述两种网络模块进行融合,得到包含编码器、解码器、分类器及MLP四个主要的子模块的混合深度学习模型,并对其采用多任务训练机制。我们认为该模型具有如下三大优势:
► 提升隐式特征相关性:采用多任务训练机制,利用解码器同时预测收益率真实值及三分类目标,能够有效提高编码器提取特征与未来收益率变化的相关性。
► 增强特征表征层次:利用编码器对输入数据进行特征压缩及关键信息抽取,将其与原始输入特征拼接,并传递到后续MLP模块中进行未来收益率预测。
► 提高模型泛化性:加入高斯噪声层对原始输入数据进行增强,避免模型过拟合;多任务训练机制一定程度上可以提高编码器模块的泛化性。
图表2:混合的深度学习模型MMLP结构
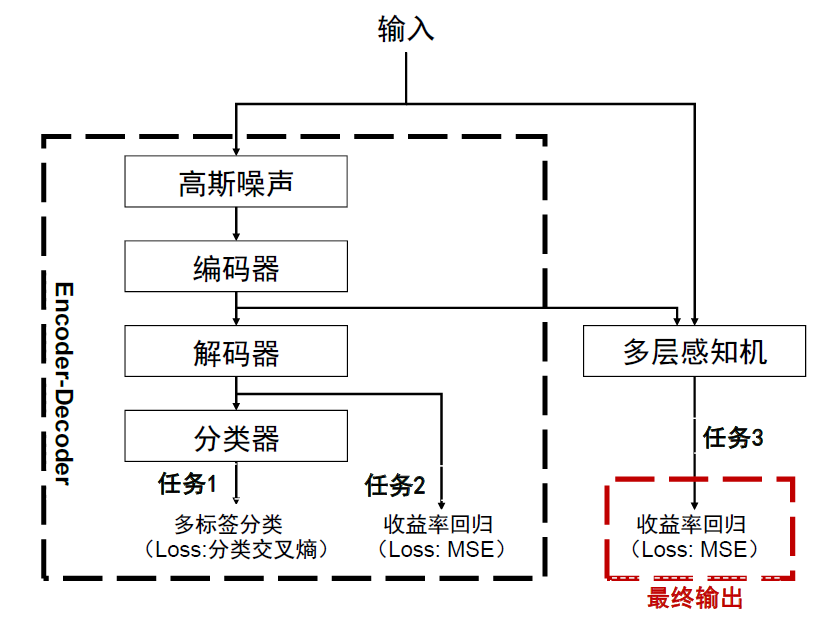
资料来源:Kaggle,中金公司研究部
单模型测试表现
模型输入的基础因子及训练框架
模型输入基础因子
我们采用的数据是基于中金量化策略团队开发的132个常见日度价量因子,27个高频因子以及88个基本面因子共247个截面选股因子。其中日度量价因子和高频因子为日度频率因子,基本面因子为月度频率因子。因子细节介绍见《量化多因子系列(5):基本面因子手册》、《量化多因子系列(7):价量因子手册》和《量化多因子系列(12):高频因子手册》。
图表3:本文使用到的主要中金量化因子类别
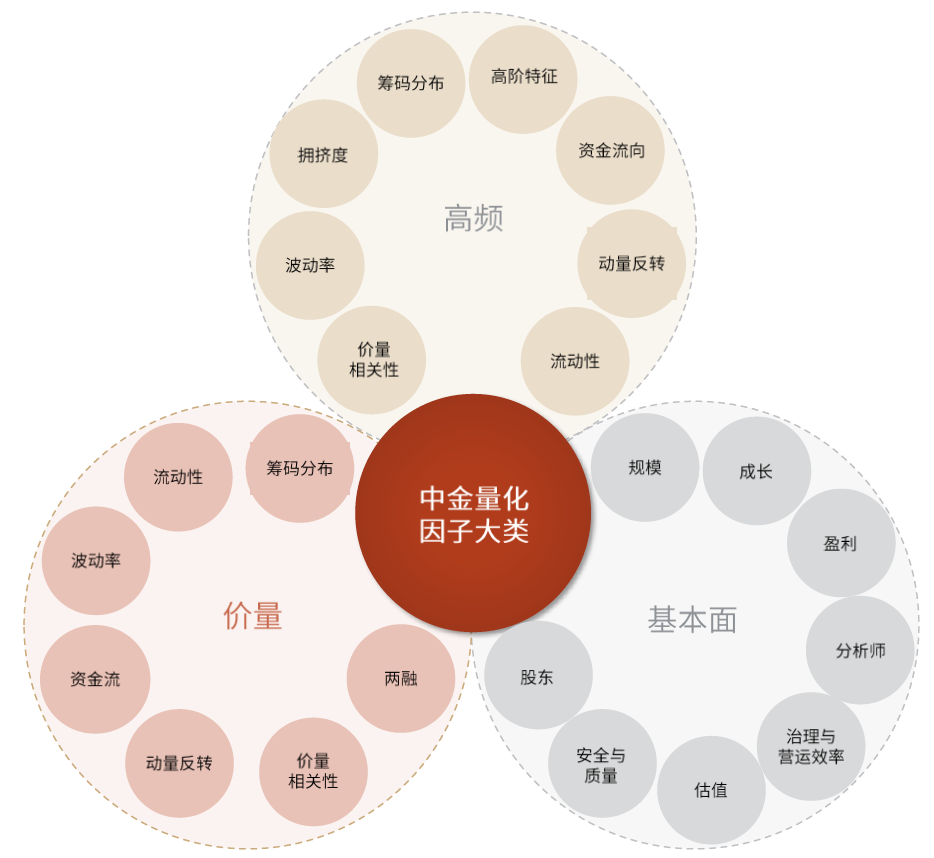
资料来源:中金公司研究部
图表4:滚动训练框架示意图
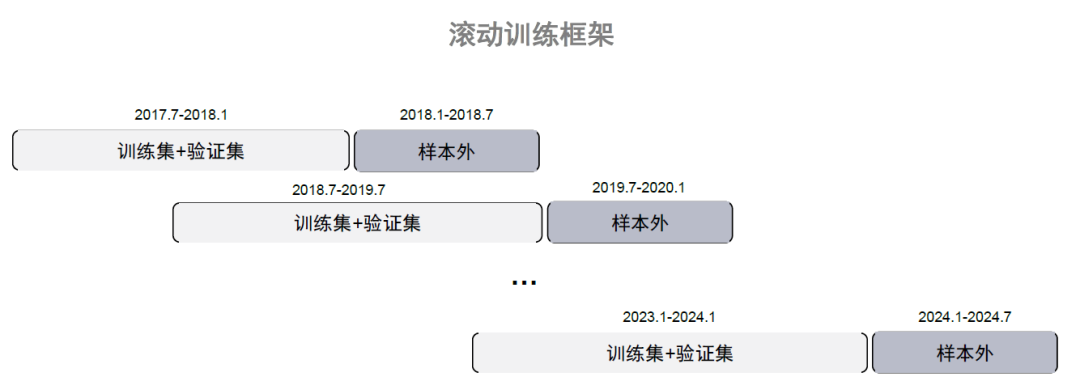
注:验证集取样本内数据最后2%,样本内和样本外中间留出空挡不用于训练避免数据泄露
资料来源:中金公司研究部
对于使用日度价量数据和高频数据的输入测试,我们将未来1日、5日和20日的收益率作为目标,对于使用月度基本面数据的测试,我们主要使用未来20日和60日目标进行测试。本文搭建的树模型以及深度学习模型分别使用开源三方库xgboost和tensorflow实现,所有实验均使用Nvidia T400显卡完成。
树模型与深度学习模型结合
树模型和深度学习模型底层结构的差异性影响了它们在不同预测目标下的性能表现。本章我们尝试将两种机器学习模型进行结合,分别采用并行与串行两种合并方式,实验结果发现合并后的因子样本外回测的结果均优于单一模型表现。
树模型与MMLP的并行结构稳定性提升
上一章我们发现树模型在预测长期目标时更具优势,而MMLP则在预测短期目标时具有更好的表现,且两种模型输出的因子存在较低的相关性系数。故本节我们采用并行结构将上述两种因子进行等权相加,以期获得更稳健的样本外表现。
具体来说,混合深度学习模型使用日度价量和高频因子作为输入,预测未来1个交易日的收益率;树模型使用基本面因子作为输入,预测未来20或60个交易日的收益率,采用默认超参数或Optuna框架调整两种超参设置方式。分别对其进行训练,按照滚动的样本外区间将两种模型的输出结果进行等权相加。我们认为,该并行结构具有如下三点优势:
► 输入特征具有多样性:输入数据囊括了高频因子、日度价量因子和基本面因子三种类型的特征,从微观和中观两个维度提供信息。
► 长短期收益预测联合建模:等权相加的预测结果来源于短期和长期两种优化目标,同时兼顾长期趋势及短期波动。
► 各具优势的机器学习模型:将具有更好稳定性及泛化性的树模型同拥有良好非线性拟合能力的深度学习模型等权结合,综合提升模型样本外收益能力的稳健性。
并行结构的样本外表现相比深度学习模型具有更加稳定的样本外表现。周度调仓下,并行结构(xgb_optuna_basic_ret20d + mmlp_tech+hf_ret1d)ICIR为0.94,相对全市场等权基准超额的信息比率为4.15,相比MMLP模型(mmlp_tech+hf_ret1d)表现分别有23.7%和1.0%的提升。
图表5:XGBoost与MMLP并行结构样本外全市场范围周度调仓表现统计

注:1)因子名称:mmlp代表混合深度学习模型,xgb代表树模型XGBoost,tech+hf代表模型输入为日度价量和高频因子,basic表示模型输入为基本面因子,ret{n}d表示预测目标为未来n个交易日后的收益率;2)此表中标注为static的树模型采用默认超参数,标注为optuna的树模型采用同名框架调参;3)统计时间为2019-01-01至2024-08-30;
资料来源:Wind,中金公司研究部
图表6:并行结构样本外全市场范围周度换仓累计IC序列对比
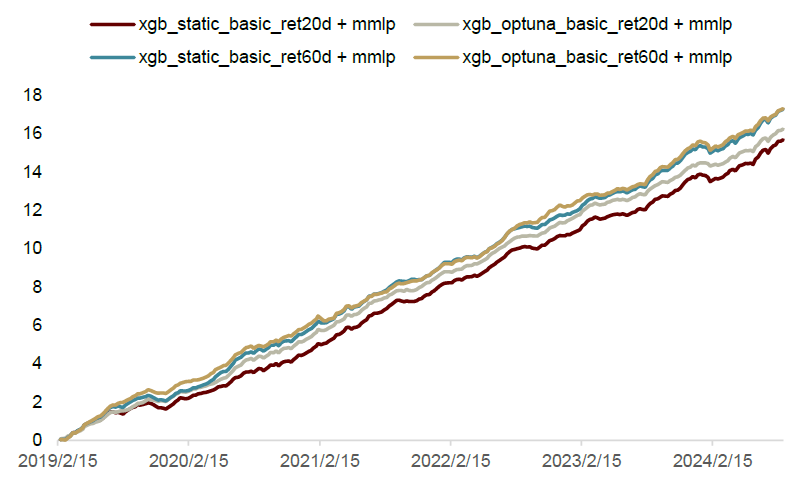
注:1)并行结构使用的混合深度学习模型输入数据为日度价量因子和高频因子,预测目标为未来1个交易日的收益率(mmlp_tech+hf_ret1d);2)统计时间为2019-01-01至2024-08-30
资料来源:Wind,中金公司研究部
图表7:并行结构样本外全市场范围周度换仓超额净值对比
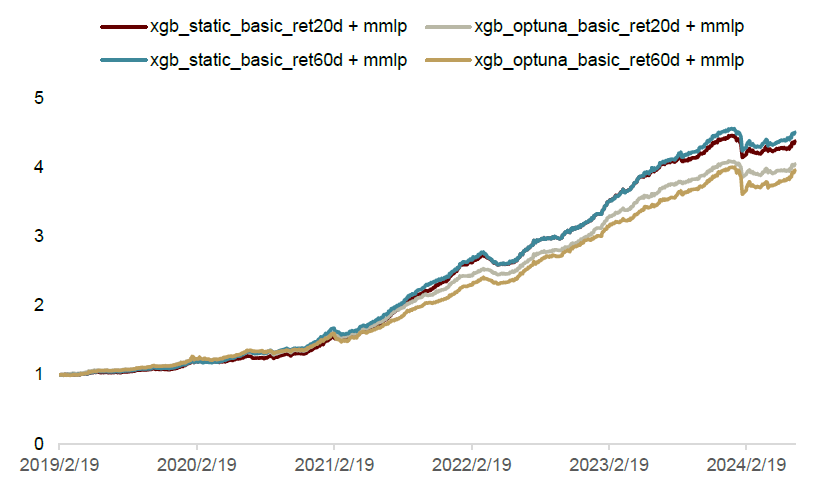
注:1)并行结构使用的混合深度学习模型输入数据为日度价量因子和高频因子,预测目标为未来1个交易日的收益率(mmlp_tech+hf_ret1d);2)统计时间为2019-01-01至2024-08-30;3)超额收益的比较基准为全市场股票等权
资料来源:Wind,中金公司研究部
我们将模型的预测结果直接用在沪深300成分股内进行测试,实验结果发现采用并行结构得到的因子相比单独的树模型及混合深度学习模型样本外的获益能力及稳定性均有显著提升。
使用MMLP隐层编码的串行结构多头超额收益更高
我们在上一章讨论得到树模型的优势在于从表格数据中筛选重要特征,而深度学习模型从原始特征中进行信息的压缩和提取更具优势,并猜想是否可以借助深度学习模型学习隐式空间的特征,再将该抽象特征传输给树模型,通过串行的方法将两者的优势结合。我们发现串行构造方法相对于单一模型可以有效提升样本外整体的稳定性及收益率。
具体来说,首先对MMLP模型进行训练,而后对其多层感知机模块最后一层隐层进行提取(样本内外数据分开操作),将其作为树模型的输入数据进行训练。MMLP训练采用的输入数据为日度价量因子和高频因子,预测目标为未来1交易日收益率;树模型的预测目标设定为未来1或5个交易日收益率两种模式。我们将隐层维度(#Dim)调整为64,128,256分别进行实验。
图表8:XGBoost与MMLP串行结构示意图
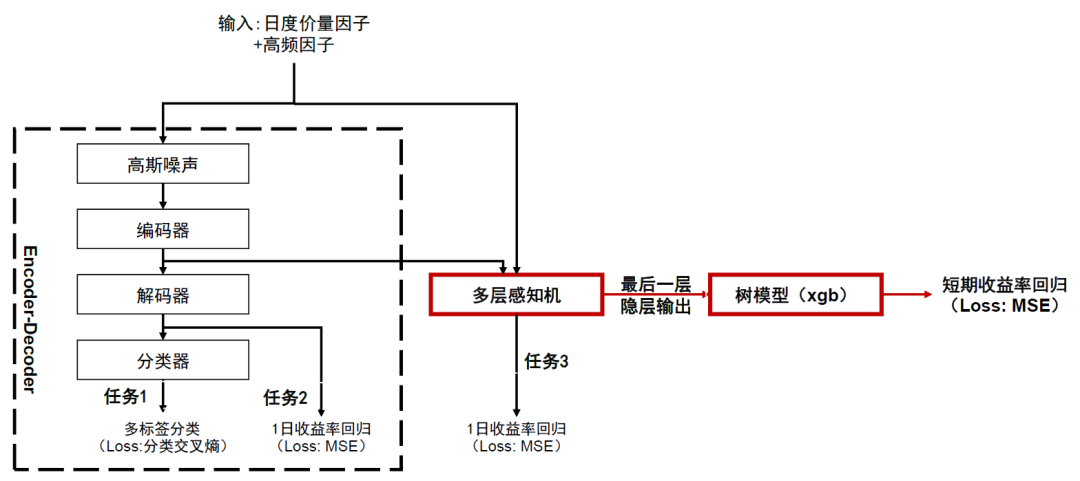
资料来源:中金公司研究部
实验结果说明,1. 64维的隐层特征值的设定能够使MMLP模型对输入数据进行较好的压缩和表达;2. 在64维隐层特征的设定下,树模型对抽象特征的解析能力明显优于混合深度学习模型的单层全连接层;3. 利用MMLP提取到的隐式特征能够有效提升树模型在短期预测目标下的性能表现,具体来说当预测目标为未来5个交易日的收益率时,使用64维抽象特征作为输入的串行结构(xgb_ret5d(#Dim=64))在周度调仓下,十分组的多头年化收益率达44.06%,相较于全市场等权基准36.85%的超额收益以及4.97的信息比率,相比同样设定的树模型(xgb_tech+hf_ret5d)在上述指标上有至少2.5倍的提升。
图表9:不同预测框架样本外全市场范围周度换仓累计IC序列对比
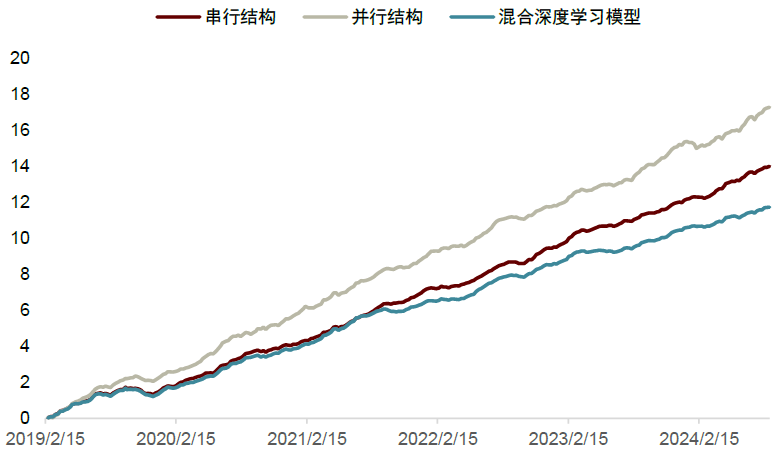
注:统计时间为2019-01-01至2024-08-30
资料来源:Wind,中金公司研究部
图表10:不同预测框架样本外全市场范围周度换仓超额净值对比
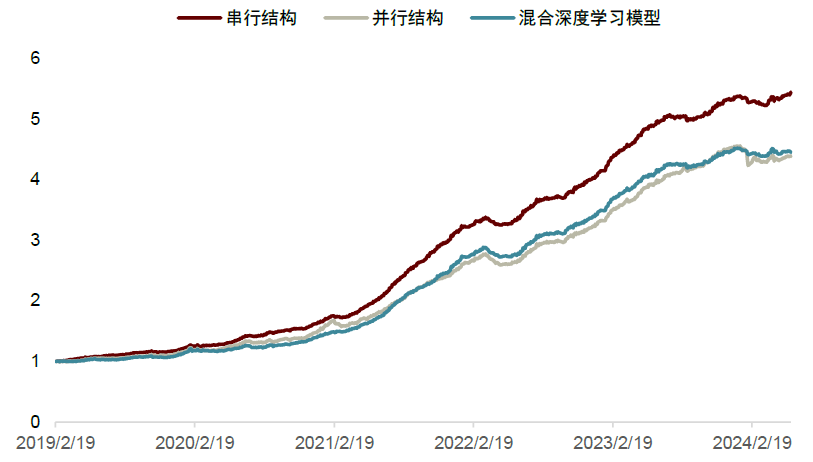
注:1)统计时间为2019-01-01至2024-08-30;2)超额收益的比较基准为全市场股票等权
资料来源:Wind,中金公司研究部
近期高波动市场下模型样本外表现持续稳定
由于近期A股市场波动较大,我们更新了上文构造的并行和串行结构截至2024年9月底的样本外表现,发现两种结构样本外仍能持续取得正超额收益,其中串行结构表现相对更佳。其近3个月多头收益率为7.8%,相较于全市场等权基准的超额收益为1.7%,多空收益为14.3%;并行结构的多头收益、相对于全市场超额和多空收益分别为6.6%、0.6%和10.1%。
图表11:并行和串行结构样本外超额净值曲线
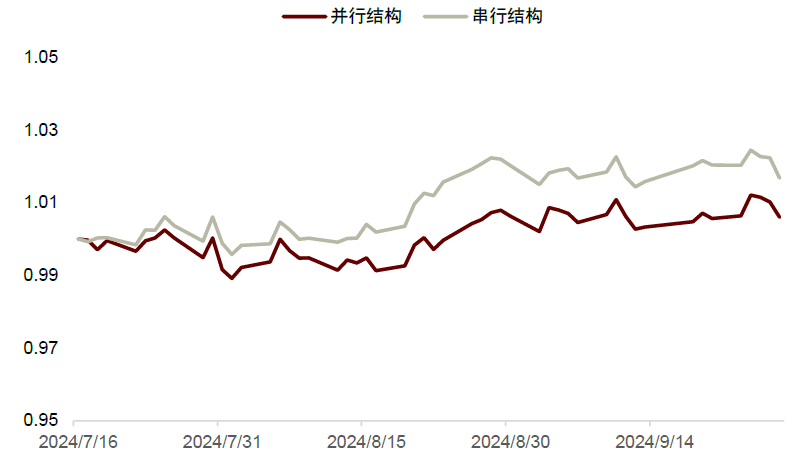
注:1)统计时间为2024-07-01至2024-09-30;2)并行结构:xgb_static_basic_ret60d + mlp_tech132_ret1d,串行结构:xgb_ret1d (#Dim=64);3)超额收益的比较基准为全市场股票等权
资料来源:Wind,中金公司研究部
图表12:并行和串行结构样本外多空组合曲线
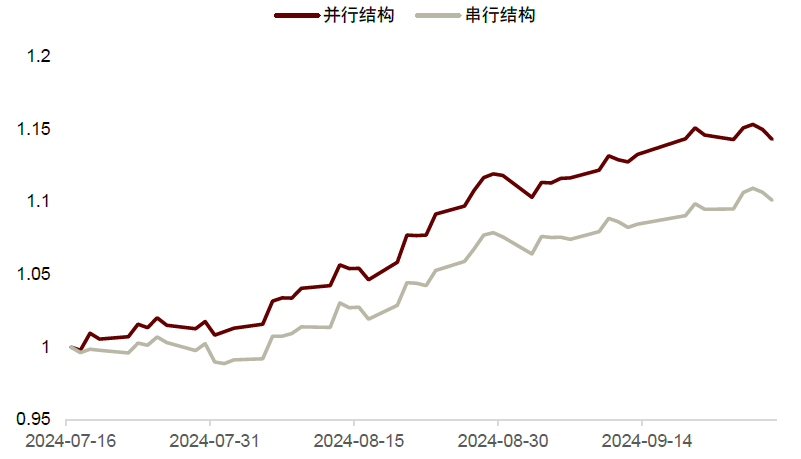
注:1)统计时间为2024-07-01至2024-09-30;2)并行结构:xgb_static_basic_ret60d + mlp_tech132_ret1d,串行结构:xgb_ret1d (#Dim=64)
资料来源:Wind,中金公司研究部
[1]Why do tree-based models still outperform deep learning on typical tabular data?.L. Grinsztajn.2022
[2]Why do tree-based models still outperform deep learning on typical tabular data?.L. Grinsztajn.2022
Source
文章来源
本文摘自:2024年10月15日已经发布的《机器学习系列(3):如何结合树模型与深度学习的优势》
分析员 郑文才 SAC 执业证书编号:S0080523110003 SFC CE Ref:BTF578
联系人 高思宇 SAC 执业证书编号:S0080124070007
分析员 周萧潇 SAC 执业证书编号:S0080521010006 SFC CE Ref:BRA090
分析员 刘均伟 SAC 执业证书编号:S0080520120002 SFC CE Ref:BQR365
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
免责声明:
您在阅读本内容或附件时,即表明您已事先接受以下“免责声明”之所载条款:
1、本文内容源于作者对于所获取数据的研究分析,本网站对这些信息的准确性和完整性不作任何保证,对由于该等问题产生的一切责任,本网站概不承担;阅读与私募基金相关内容前,请确认您符合私募基金合格投资者条件。
2、文件中所提供的信息尽可能保证可靠、准确和完整,但并不保证报告所述信息的准确性和完整性;亦不能作为投资决策的依据,不能作为道义的、责任的和法律的依据或者凭证。
3、对于本文以及文件中所提供信息所导致的任何直接的或者间接的投资盈亏后果不承担任何责任;本文以及文件发送对象仅限持有相关产品的客户使用,未经授权,请勿对该材料复制或传播。侵删!
4、所有阅读并从本文相关链接中下载文件的行为,均视为当事人无异议接受上述免责条款,并主动放弃所有与本文和文件中所有相关人员的一切追诉权。
