
李琦:如何用AI和遗传算法战胜亚洲市场宽基指数?
作者:建榕量化研究
题图:建榕量化研究 微信公众号
会议:开源证券2025年度策略会
议程:量化投资与资产配置论坛
日期:2024年11月13日
地点:上海浦东香格里拉酒店
主办:开源证券金融工程魏建榕团队
主题演讲:如何用AI和遗传算法战胜亚洲市场宽基指数?
特邀嘉宾:李琦,平安财产保险资产管理部战略资产配置负责人(个人微信号:15316584798)

发言实录:
大家好,感谢开源证券金融工程团队魏建榕博士的邀请!我是来自平安财产险资产管理部李琦,我们团队主要负责战略资产配置和一部分的MOM、FOF、固收+和深度学习。今天的主题叫如何用AI和遗传算法战胜亚洲市场宽基指数,和大家分享一些我自己的研究。
首先在深度学习模型下,AI在投资领域其实有很多的贡献,一方面可以做资产配置,另一方面就是指数择时,第三部分是在横截面。横截面的应用场景,更多的是我们做指数增强,或者如果在其他国家市场的话可以基于横截面选股的那一套因子去做多空组合,然后做绝对收益。
在横截面上,我们可以看到有三个很严峻的挑战:第一个挑战是在于因子。我们通常有两种因子,一种是线性的因子,一种是非线性因子。所谓的线性因子就是能够用人的大脑非常清晰的认识到,如果一个因子好,那么它对股市就会有预测作用,也就是说我们用统计学上的相关系数可以有效的去衡量,通常的衡量指标是用rankIC等。然后第二种是非线性因子,就是我直接用这个因子对预测可能起不到一定的作用,但是通过一些非线性转化,我希望最终转换出来的因子和未来的涨跌幅有一定的关系。我们当然可以通过基本面,技术面和另类数据构建因子。但核心的问题在于,如果因子本身它的rankIC不高,只有7%,是否有更好的方法让这一些rankIC不高的因子变废为宝,把它提升到12%。所以横截面选股的第一个挑战在于我们是否有一套数据放大的方式,将一些rankIC不高的因子变废为宝,把它从smart Beta 因子转换成alpha因子。第二个挑战是在于模型的参数。当我们提到深度学习模型的时候,其实有两种参数,一种是模型自身的参数,比如说深度学习中最简单的 MLP 模型。我们的核心逻辑是 Wb+c,然后通过各种激活函数来激活,那么W和b就是一个模型参数;第二种参数是超参,比如说CNN、LSTM中它的 batch size,learning rate,layers等。我们如果把这个问题交给一个统计学或者机器学习的博士,他会告诉你一些基于人的经验制定超参。这是一个很好的方法,也是我们花重金去招募各种优秀人才的一个初衷。但是如果我们能够找寻一套很好的自动的寻找超参的方法的话,那么这样就可以尽量的减少对人的依赖。第三个挑战在于,当我们的模型特别多,面临着不同的DNN的深度模型以后,如何有效地将不同的网络模型进行有效的结合。

下面的主题是因子方面,传统来说也就是我前面说的线性因子方面,有基本面因子,技术面因子和一些另类因子,这是我们大家花很大的力气想挖掘的因子,但是按我前面的定义了,这些因子还是比较偏线性,当这些因子本身的 rank IC 不高的时候,其实需要考虑一些方法,要么挖掘新因子,要么使用一些深度学习或者机器学习方法进行合成,那么就是带入我们左边的这些所谓的结构化因子。问题是,如何把这些因子进行有效整合?第一种传统量化方法,可以用线性因子通过 ICIR 的各种方法去结合。然后其他两个方法,一个是machine learning,一个是 deep learning,这两个其实区别还是非常大的。在现在市场上的量化私募里面,尤其是头部量化私募,我们会观察到当目前一段时间alpha突然衰减的时候,我们就会发现有两个阵营:有一部分的量化私募,它的alpha还在上升,而另外一部分量化私募,它的alpha在衰减。可能他们底层用的模型,一部分是用的machine learning,一部分人用的deep learning。当然这个跟每个团队原始的背景,以及它的网络架构有很大的关系。简单来说,machine learning更多的使用 CPU 驱动的一些方法,比如说大家比较熟知的XGBoost、SVM。另外一部分人更多的使用深度学习以 GPU 为导向的方法。
这一页我花了一些时间找寻了一些关于machine learning方面的文章,更多的还是从 2017年到 2024 年的海外 SCI 的文章,是对于深度学习machine learning和时序横截面的一些文章的收集。在横截面选股里面到目前为止引用量最大的一篇文章是2018年Fisher的文章,这篇文章把所有的细节都进行了展示,input、feature就是return,预测的就是未来5天的return,用的模型是LSTM,在这个模型中有多少神经元,有多少层,全部详细的记录这篇文章中。看起来很简单,但这个因子它最终的rank IC可以达到9%。然后在此基础之上,除了简单的将一些传统因子放入神经网络以后,也有一部分人曾经想过在数据层面做一些改进。比如可以把数据集放大,用 PCA 的方法对数据进行降维,甚至是做一些小波分解,去掉噪声因素,如季节因素等。
当你确定了神经网络的参数以后,如何对这些神经网络的模型进行调优(tuning)?实际上,从2020到2021年间,许多非金融领域的专家也在不断地对神经网络进行调参。比如,有些人采用神经网络来预测地震或洪水等自然灾害。例如,印尼每天许多地区都可能发生洪水,其实这个问题与投资领域的挑战非常相似。我们依然是将洪水相关的数据输入到神经网络中,以预测是否会发生洪涝灾害。然而,核心问题依旧是:如何调整这些模型的超参数?针对这一问题,很多期刊提供了多种方法,介绍了如何利用模型来自动优化超参数的各种技术。总结下来,有三种方法可以用于神经网络的超参数调优:第一种是基于遗传算法,第二种是基于粒子群优化(PSO),第三种是基于贝叶斯优化。到底哪种方法更好,需要通过实证分析来验证。
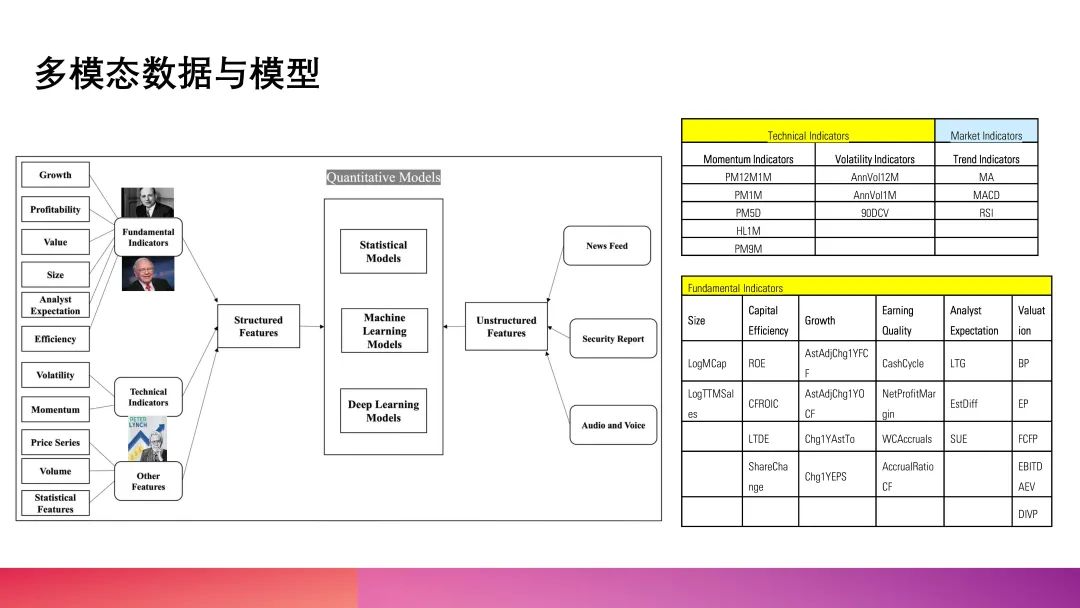
在介绍这些方法之前,首先分享一下我们团队搭建的神经网络框架。我们使用不同类型的因子,包括基本面因子、技术面因子以及量价因子,并在中间进行去噪和标准化处理。第二步非常关键,这一步关系到如何变废为宝。比如,假设你原本有200个因子,而这些因子的rank IC平均值大概只有4%。有没有一种方式可以在第二步时,将这些因子在输入神经网络之前的rank IC从4%提升到9%?这就是如何进行数据放大、将低效因子变得更加有用的问题。当我们完成数据放大后,把这些放大的数据输入到神经网络中。当然,神经网络的种类非常多,目前比较常见的版本包括LSTM、Transformer,以及今年推出的MAMBA模型等。这些模型都可以作为神经网络的基础框架,将经过放大处理的数据输入其中。当你使用了这些神经网络模型后,就会发现,不同的模型在参数和超参数的选择上差异很大。例如,假设你已经使用LSTM模型3年,非常熟悉它的使用方法。那么现在有一个新模型,比如MAMBA模型,它的超参数比LSTM更多,面对这种情况,你需要有效地根据数据的本质特征去调节这些超参数。这也正是我今天分享的重点——如何进行超参数优化。当超参数优化完成后,整套流程下来,最后就得到了一部分合成因子,我们期待这个因子,它的RankIC达到 10%- 20%,最后把这个因子用在优化器中做指数增强,这个就是我在这个数据放大层面画了一个这个流程图。
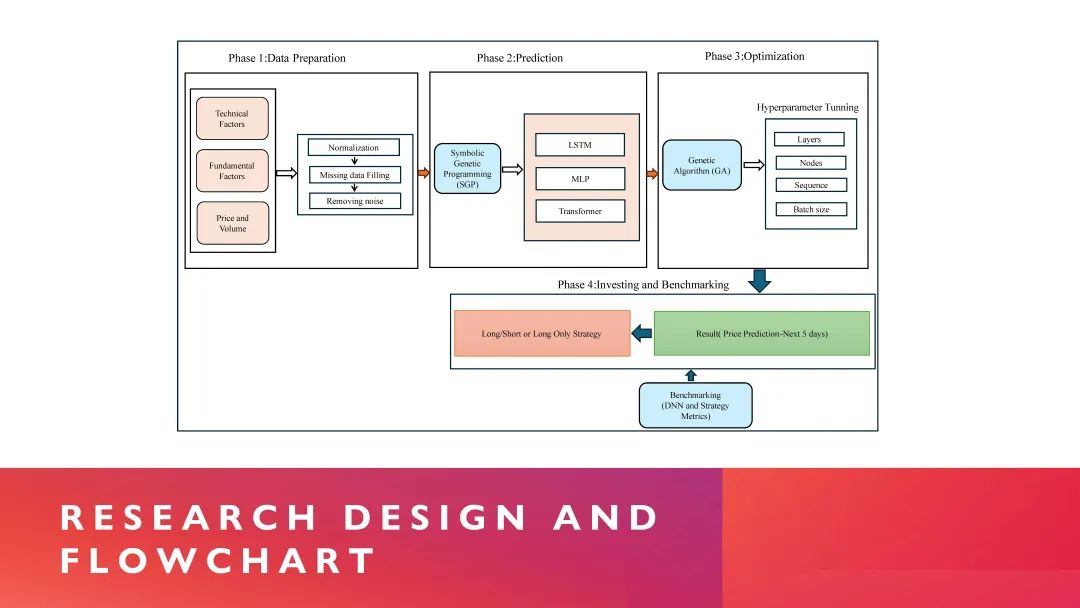
重点在于如何通过数据放大的方式实现“变废为宝”。在数据放大之前,你有三个可以调整的关键因素:一个是因子值;第二个是公式,公式的选择灵活多样,既可以是线性公式,也可以是非线性公式;第三个是滚动窗口,通过滚动窗口可以动态调整数据的取样方式,从而捕捉不同时间维度的数据特征。通过这套方法,可以将原本200个因子的数量扩展到20000个。接下来,使用一套自定义的筛选方法,将这20000个因子整合成2000个因子。这些因子的RankIC指标将会从原本的约5%提升到10%左右。最后再将这些经过筛选和优化的因子输入到神经网络中进行进一步的优化。具体到实际应用,比如基本面因子和价量因子的整合,其基础的IC均值通常是不高的。关键在于如何有效地整合这些因子。整合的方法可以是将所有因子一次性输入到一个网络中,也可以是先将部分因子集进行数据放大,再与其他因子集结合,最后加入一个复杂的网络进行整体优化。当然,这种整合方法涉及到很多技术细节,相关的研究文献也非常丰富。
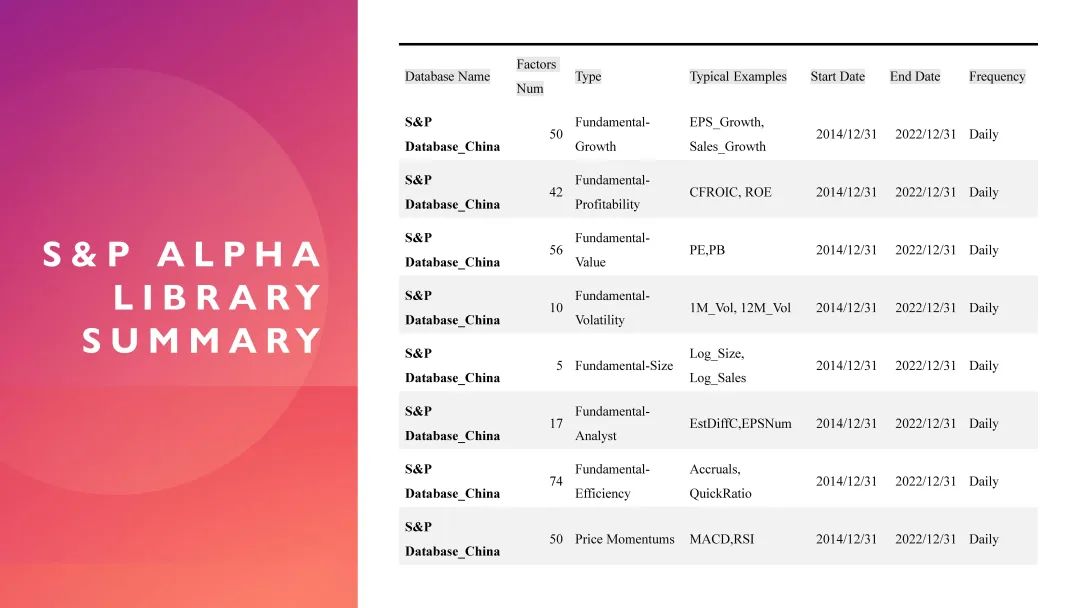
那么我这里对比了一下中国和东亚其他国家市场,这可能是大家比较关心的主题。现在很多人都在关注,如果未来中国的利率一路下行,中国市场会不会逐渐走向类似东亚其他国家市场的状态?东亚其他国家市场最大的一个特点就是它的利率非常低。在这样的低利率环境下,我们会关心这个国家的alpha是否仍然维持在较高水平,或者说其中是否存在某种对应关系。我们团队在线下做了很多关于中国alpha的研究,基本上可以得出一个共识:中国市场的alpha水平大致稳定在9%到10%左右这个数量级。而当东亚其他国家的利率一路下降到1%时,市场的alpha是否还能维持在9%到10%这个水平?如果可以维持,理论上就可以通过不断加杠杆来放大alpha收益。所以我用同样的方法分析对比中国市场和东亚其他国家市场。首先,我们查看了一些基本面和技术面因子。我引用的是标普的数据库,这个数据库中包含大约240个因子,并进行了分类汇总。我们发现:原本的基本面因子在东亚其他国家市场和中国市场的均值都不高;而技术面因子方面,中国市场的数值比东亚其他国家市场高出了一倍。这从数据上给了我们一个直观的感受:中国市场更适合使用价量因子来构建神经网络,而东亚其他国家市场可能更适合使用基本面因子来解释市场行为。进一步分析来看,可能是因为东亚其他国家市场越来越趋于理性,投资者的过度反应逐渐减少,股市中的alpha也随着时间的推移逐渐消失了。
接下来讨论目前的结果。模型的结果和策略的结果我分成了两个部分,分别放在左边和右边。首先,当你将所有的数据放到神经网络里面以后,如果直接用策略的业绩来衡量其实是不科学的。因为本质上,这件事情更像是一个神经网络的游戏,是一个纯粹的深度学习问题。所以,我选择使用一些深度学习的指标来衡量,比如说rankIC、accuracy,以及它的recall和AUC等。左边是A股市场的表现,右边是东亚其他国家市场的表现。我们可以看到,经过数据融合和模型优化后,A股市场的rankIC大约在10%左右,而东亚其他国家市场的rankIC大约在4%左右。然而,东亚其他国家市场由于可以进行多空操作,其尾端效应更强。所以在东亚其他国家市场做多空操作后,它的performance Alpha接近超过10%。
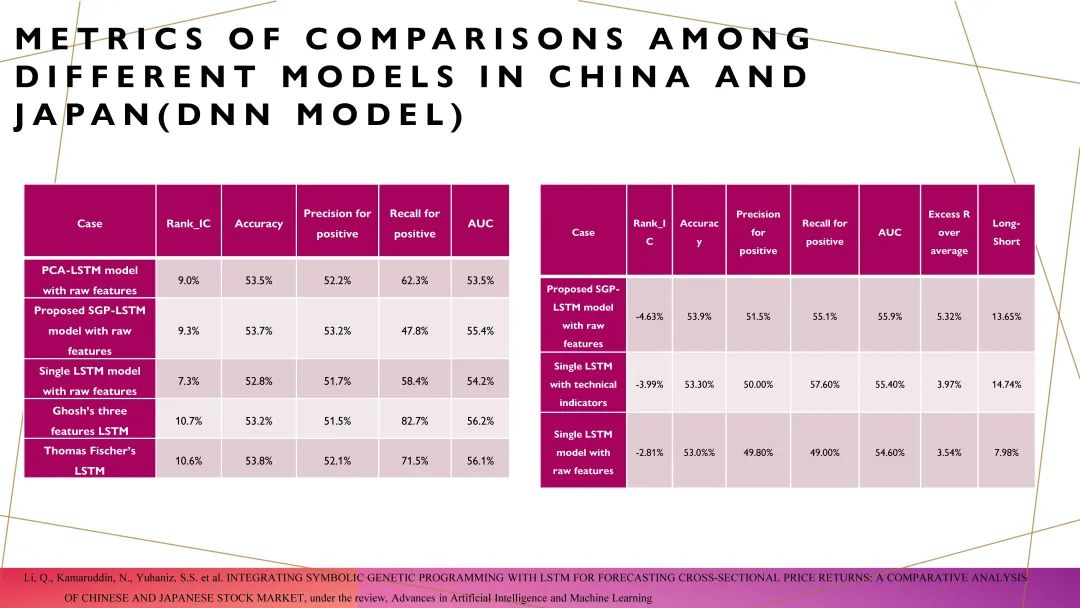
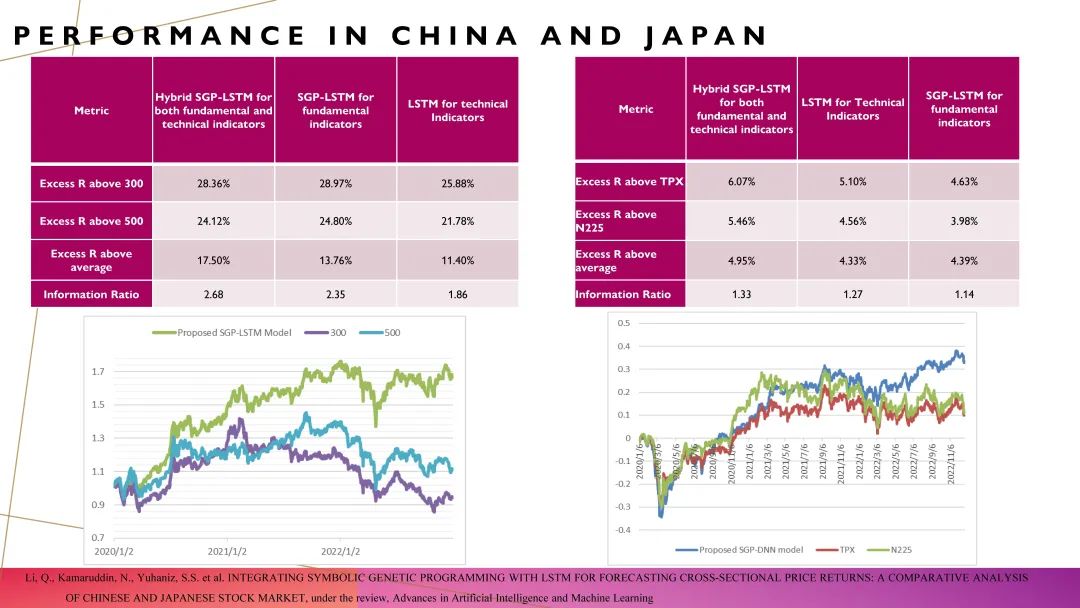
接着,我们对比了SGP模型在两个市场中的应用效果。在过去4到5年间的超额收益情况中,东亚其他国家市场的利息较低,可以通过加杠杆来放大收益。加杠杆之后,东亚其他国家市场的alpha水平和A股市场的水平就更加接近了。
最后回到刚才提到的超参优化问题。这里有一张图,它和之前的图很接近。左边展示的是基础模型,而右边则侧重于超参优化的部分。超参的范围非常广,比如神经元的个数、batch size、网络的层数(layer)等等。在我的这篇文章中,我提出了一种“两步走”的优化方法,这个方法结合了几种常见的超参优化算法,比如贝叶斯优化(Bayesian Optimization)、遗传算法(GA)和粒子群优化(PSO)。具体来说,这个方法分为两个步骤:第一步是利用贝叶斯优化,第二步是使用遗传算法(GA)。首先,我们通过贝叶斯优化在大范围内快速锁定一个潜在的高效区域。举个例子,当我们去“淘宝”时,如果需要在全世界范围内寻找某样宝物,贝叶斯优化相当于告诉我们“非洲有宝,而不是亚洲有宝”。通过这种方式,我们不需要在全球100个国家都投入人力,而是直接将精力集中在最可能有宝的区域。第二步,在贝叶斯优化锁定的区域内,我们再通过遗传算法进行精细化搜索。遗传算法擅长在局部范围内找到最优解,相当于我们已经确定了非洲大陆有宝物,接下来就通过遗传算法逐步筛选出具体的细节,比如哪个国家、哪个地区,最终找到最优结果。
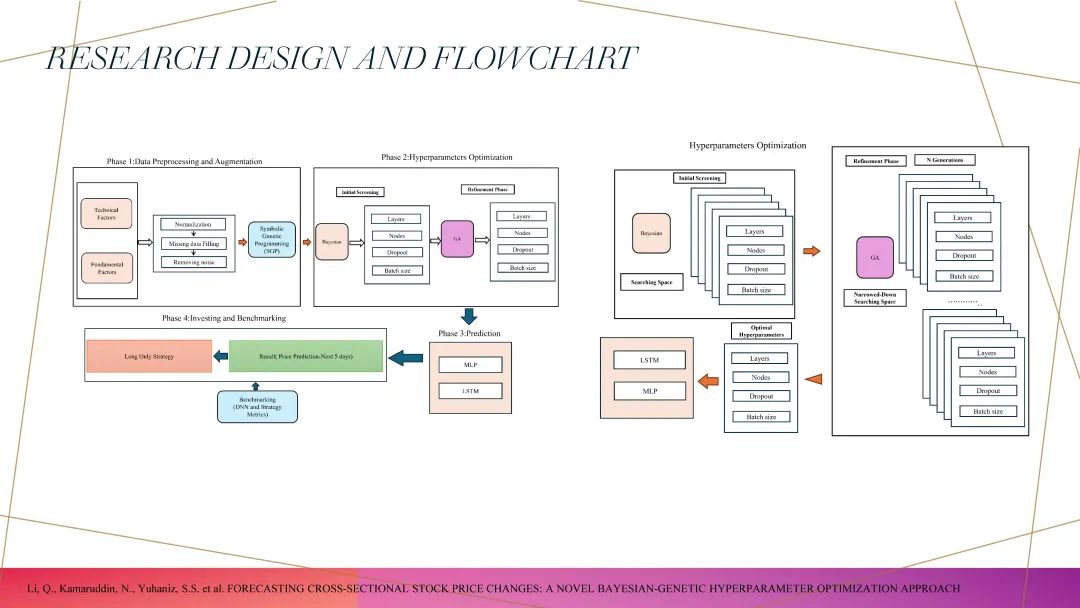
这种“两步走”的方法结合了贝叶斯优化的高效性和遗传算法的精确性。贝叶斯优化帮助我们在大范围内快速缩小搜索空间,而遗传算法则在这个空间内进一步挖掘局部最优解,从而实现对超参的高效优化。这只是一个简单的描述,通过这样的方式,可以进行下一步试验。在这个试验中,我首先将超参定义为五个主要方面。以LSTM为例,这五个方面包括LSTM的层数、LSTM的dropout、LSTM的神经元数,以及MLP的神经元数,学习率等,这些超参的搜索空间通常非常大。在这种情况下,传统方法往往依赖于人力,由具有丰富经验的研究人员在搜索空间中找到合适的超参。而在这篇文章里提出了一种更加高效的方法:通过机器自动筛选来确定最优的超参。

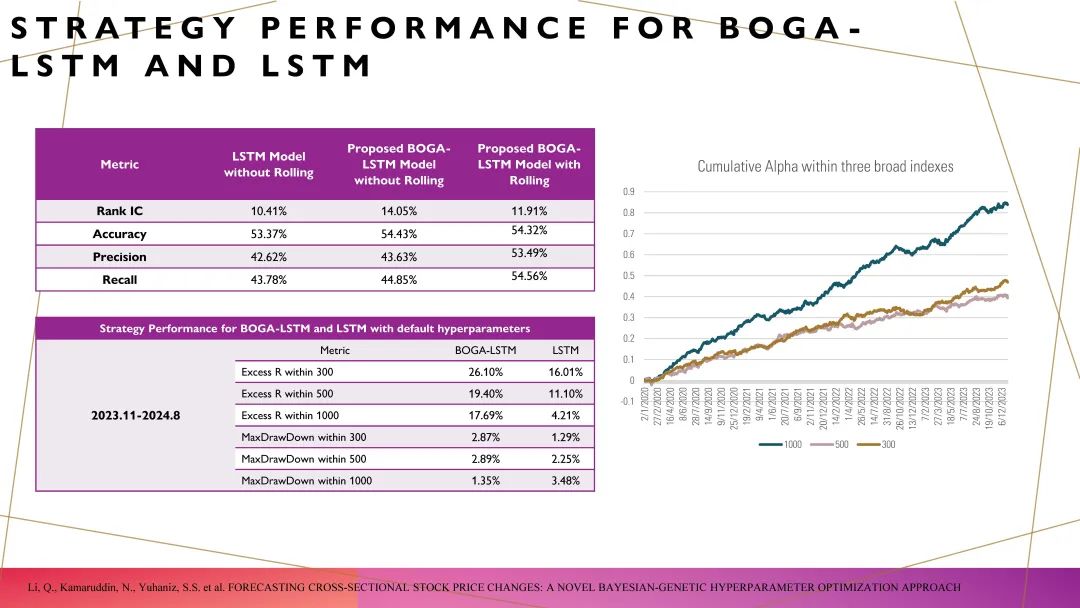
我首先对比了使用贝叶斯优化和遗传算法(GA)进行超参优化后的效果。原本这些因子的RankIC大约只有3%。通过SGP优化,RankIC提升到了9%。然后,经过进一步的超参优化后,RankIC又提升到了13%。左边和右边使用的是两种不同的方法。贝叶斯优化是一种数学优化方法,它的最大优点是计算速度非常快;但是,贝叶斯优化的缺点是,它未必能够找到全局最优解,容易陷入局部最优。而右边的遗传算法(GA),则能够更方便地找到全局最优解,最大的问题是,它的计算成本非常高。你可能需要用一台高性能的计算机进行优化,可能两周的时间才能完成。
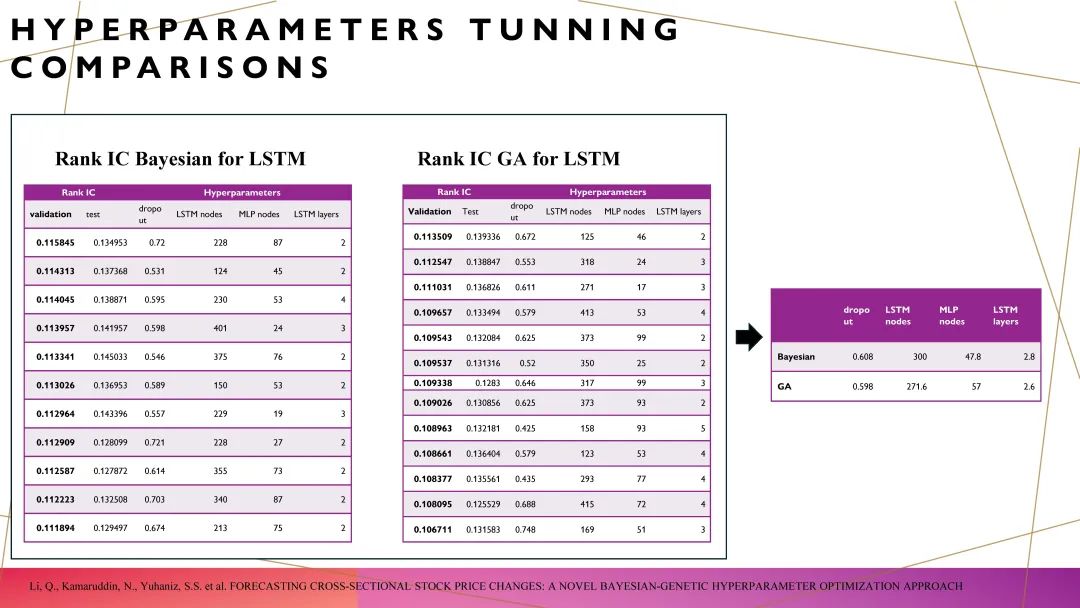
因此,最理想的方式是将贝叶斯优化和遗传算法结合起来使用。这就像我刚才提到的例子:左边的贝叶斯优化就像是在全世界范围内以最快的速度定位到“非洲有黄金”;右边的遗传算法则是在确定“非洲有黄金”的情况下,在非洲大陆内部进行全面探索,找到具体的黄金位置。这样,贝叶斯优化通过快速缩小搜索空间,帮助我们迅速找到潜在的最优区域,而遗传算法则负责在这个区域内进行详细的精细化搜索。所以自然的考虑是,将贝叶斯优化和遗传算法进行融合,实施“两步走”策略。第一步,使用贝叶斯优化在大范围内快速缩小搜索空间,定位到潜在的最优区域;第二步,使用遗传算法对这个较小的区域进行深入挖掘,最终找到最优的超参配置。通过这种方法,我们能够高效地进行超参优化,实现了计算效率和优化精度的平衡。

经过这个试验后,我还比较了基于BOTA优化的LSTM模型与纯粹LSTM模型在300、500、1000的增强效果以及最大回撤。大家可以看到,最大回撤相对较小,这是因为我在整个过程中使用了优化器,原本定义了它的跟踪误差控制在3%,因此在样本外的回撤较小。这样一来,Calmar比率会相对较高,而信息比率未必特别高。以上就是我今天的分享,如果大家在线下对整个报告有兴趣的部分,欢迎与我进一步沟通,谢谢大家。
(全文结束)
(纪要整理:孙蘅)
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
免责声明:
您在阅读本内容或附件时,即表明您已事先接受以下“免责声明”之所载条款:
1、本文内容源于作者对于所获取数据的研究分析,本网站对这些信息的准确性和完整性不作任何保证,对由于该等问题产生的一切责任,本网站概不承担;阅读与私募基金相关内容前,请确认您符合私募基金合格投资者条件。
2、文件中所提供的信息尽可能保证可靠、准确和完整,但并不保证报告所述信息的准确性和完整性;亦不能作为投资决策的依据,不能作为道义的、责任的和法律的依据或者凭证。
3、对于本文以及文件中所提供信息所导致的任何直接的或者间接的投资盈亏后果不承担任何责任;本文以及文件发送对象仅限持有相关产品的客户使用,未经授权,请勿对该材料复制或传播。侵删!
4、所有阅读并从本文相关链接中下载文件的行为,均视为当事人无异议接受上述免责条款,并主动放弃所有与本文和文件中所有相关人员的一切追诉权。
