
作者:量化投资学
题图:量化投资学微信公众号
在上一篇文章《量在价先(上):如何利用成交量预测市场走势》中,我们参考光大证券的研究报告《放量恰是入市时,成交量择时初探》,介绍了用成交量进行择时的一个思路:对成交量进行时序排名,然后根据排名的大小择时交易。本文以沪深300指数为例,介绍如何用Python实现成交量时序排名择时策略,并观察策略的择时效果。
一、获取基础数据
1. 导入需要的库
# 导入需要使用的库
import pandas as pd
import numpy as np
import akshare as ak
# 在matplotlib绘图中显示中文和负号
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family'] = 'STKAITI' # 中文字体'STKAITI'
plt.rcParams['axes.unicode_minus'] = False # 解决坐标轴负数的负号显示问题
# 关闭警告信息
import warnings
warnings.filterwarnings('ignore')2. 从AKShare数据源获取沪深300指数的数据
关于AKShare的使用,可以参看后附的文章《如何用AKShare获取金融数据》。AKShare的接口有时会有变动,如果获取数据出错请参考AKShare的官网解决。
# 获取指数数据
index_code = 'sh000300'
start_date = pd.to_datetime('2005-01-01')
end_date = pd.to_datetime('2023-12-31')
price_df = ak.stock_zh_index_daily(symbol=index_code)
price_df['date'] = pd.to_datetime(price_df['date'])
price_df = price_df[(price_df['date']>=start_date) & (price_df['date']<=end_date)]
price_df = price_df.sort_values('date').set_index('date')上述代码用AKShare的stock_zh_index_daily()接口获取沪深300指数从2005年到2023年的行情数据。数据格式如下:
二、计算成交量时序排名
成交量时序排名的计算方法是:根据包括当日在内的过去N个交易日的成交量数据, 从小到大排序,计算当日成交量的排名,然后将排名标准化到 [-1, 1] 的范围内。
相关代码如下:
# 计算成交量时序排名
# 设置滚动窗口的大小
N = 40
# 计算排名
price_df['ranked'] = price_df['volume'].rolling(window=N).apply(lambda x: x.rank().iloc[-1], raw=False)
# 标准化排名到[-1, 1]范围
price_df['normalized_rank'] = (price_df['ranked'] * 2 - (N + 1)) / (N - 1)上述代码使用rolling()函数创建一个滚动窗口(窗口大小为N),然后使用rank()函数计算该窗口内的成交量排名ranked。最后使用公式 (ranked * 2 - (N + 1)) / (N - 1) 来将排名转换为[-1, 1]范围内的值。
三、根据成交量时序排名择时
1. 计算择时信号
择时规则为:确定开平仓阈值s,当成交量时序排名的标准化值超过阈值s时开仓;当成交量时序排名的标准化值低于阈值s时清仓。
# 成交量时序排名择时信号:成交量时序排名高于阈值s时开仓,低于阈值s时清仓
s = 0.5 # 择时阈值
timing_df = pd.DataFrame()
timing_df['成交量时序排名'] = (price_df['normalized_rank'] > s) * 1.
timing_df['不择时'] = 1.本例将开平仓阈值s设为0.5,由于标准化后的成交量时序排名在[-1, 1]的范围内,0.5属于中上位置。
上述代码将开仓信号设为1,清仓信号设为0。
2. 计算择时收益
# 计算指数每日的收益率
price_df['returns'] = price_df['close'].pct_change().shift(-1).fillna(0)
# 计算择时后的每日收益率
timing_ret = timing_df.mul(price_df['returns'], axis=0).dropna()
# 计算择时后的累计收益率
cumul_ret = (1 + timing_ret.fillna(0)).cumprod() - 1.上述代码将日收益和择时信号相乘,如果择时信号为1,则保留该日收益;如果择时信号为0,则该日收益为0。然后计算累计收益。关于各种收益的计算,可以参看后附的文章《一文讲清7种收益率的python实现》。
3. 可视化择时效果
# 可视化输出
cumul_ret.plot(figsize=(10, 6), title='成交量时序排名择时')结果如下:
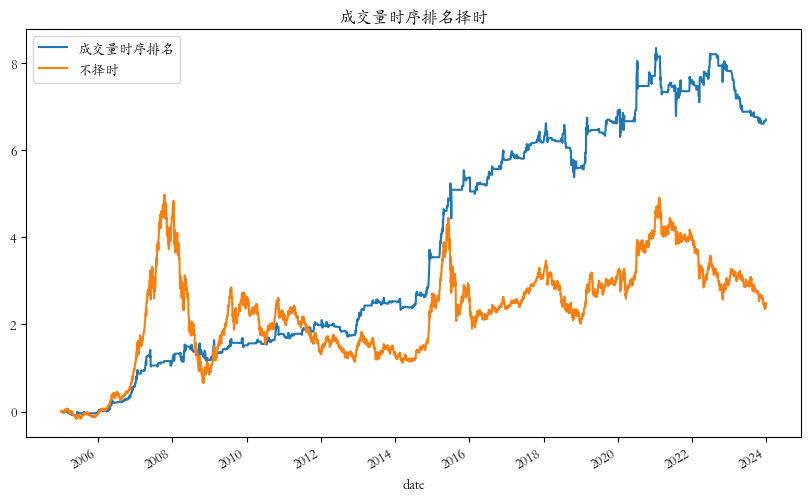
从上图可以看出,成交量时序排名择时策略取得了较明显的择时收益。同时,该策略也是一个保守的择时策略,该策略在风险控制方面表现出色,尤其在对最大回撤的控制上。但在牛市期间,该策略可能会错过一些市场上涨的机会,因为它需要成交量达到一定的阈值才会发出买入信号。这种特性导致在快速上涨的市场中,策略可能会显得较为保守,从而踏空一部分收益。
四、策略改进:在划分市场状态的基础上应用成交量时序排名择时
由于成交量时序排名择时在在牛市期间比较保守,可能会错失部分收益,一个改进的思路是先将市场划分为牛市、熊市和震荡市三个状态,然后在不同的市场状态下适用不同的开平仓阈值:
牛市阈值较低,在成交量稍有增加(甚至是没有明显缩量)时就能够进行买入操作。
熊市阈值较高,只有在成交量显著增加时,才可能触发买入信号。
震荡市阈值中等,在成交量有适度增加时进行交易。
划分市场状态的方法可以计算过去若干日的指数涨幅,如果涨幅大于某个阈值c则认为是牛市;如果涨幅小于-c,则认为是熊市;否则是震荡市。
1. 划分市场状态,并根据市场状态设定开平仓阈值
# 根据不同行情设置不同的交易阈值择时
Sf = 0.6 # 熊市阈值
Sc = 0.3 # 震荡市阈值
Sr = 0 # 牛市阈值
days = 10 # 涨跌幅天数
c = 0.05 # 涨幅阈值
# 计算指数涨幅
price_df[f'ret_{days}'] = price_df['close'].pct_change(days)
# 指数涨幅大于c为牛市,择时阈值设为Sr;指数涨幅小于-c为熊市,择时阈值设为Sf;其余为震荡市,择时阈值设为Sc
price_df['thre'] = Sc
price_df['thre'].loc[price_df[price_df[f'ret_{days}']>c].index] = Sr
price_df['thre'].loc[price_df[(price_df[f'ret_{days}']<-c)].index] = Sf2. 计算择时信号
# 计算不同行情下的择时信号
timing_df['成交量时序排名_分行情'] = (price_df['normalized_rank'] > price_df['thre']) * 1.3. 计算择时收益
# 计算择时后的每日收益率
timing_ret = timing_df.mul(price_df['returns'], axis=0).dropna()
# 计算择时后的累计收益率
cumul_ret = (1 + timing_ret.fillna(0)).cumprod() - 1.4. 可视化择时效果
# 可视化输出
cumul_ret.plot(figsize=(10, 6), title='成交量时序排名择时')结果如下:
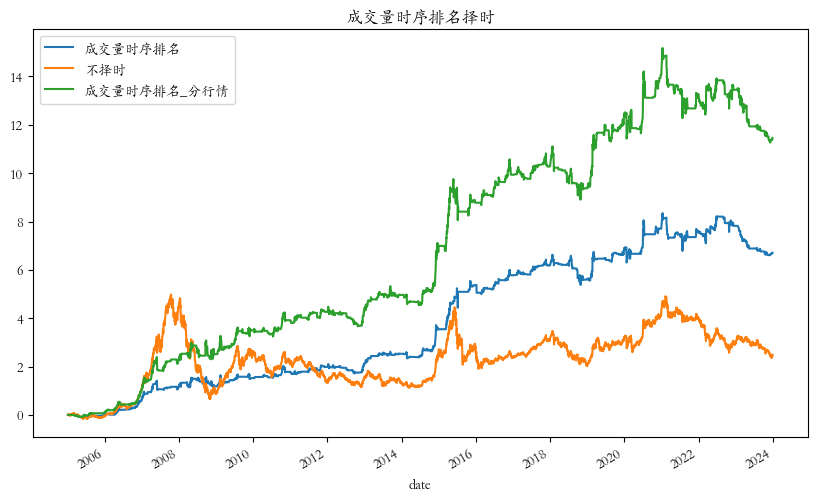
从上图可见,在划分市场状态的基础上对策略进行改造之后,策略的择时收益有了明显提高。
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
