
A 股市场中的科技动量
作者:川总写量化
题图:川总写量化微信公众号
摘要
本文针对 A 股,使用 BGE 大语言模型构造并检验科技动量效应。实证结果表明,基于 BGE 和基于 IPC 分类构造的科技动量是互补而非替代关系。二者均含有关于 cross-section 的预测信息。
0 引言
如今,各位对另类数据早已不再陌生。在另类数据的应用中,各种“花式动量”(即从不同信息源所构造的企业间关联导致的动量溢出效应)最深入人心。
早在几年前,Lee et al. (2019) 使用专利数据针对美股构造了科技动量异象,它可以获得常见风险因子无法解释的超额收益。在构造科技动量时,该文使用专利的 IPC 分类(本文附录 A 对 IPC 分类进行了简介),得到每个公司的专利分类分布,然后计算公司分布之间的两两余弦相似度(相似度越高说明二者的关联越强)。之后,Bekkerman et al. (2023) 升级了度量相似度的方法。与前文不同,该文没有使用 IPC 分类,而是直接对专利进行文本分析,通过提取专业术语并计算其重合度来描述公司之间的相似程度。
一旦有了相似度,便可以按照如下的方法构造科技动量变量:

近年来,专利数据在 A 股市场中的实证研究也不在少数。鉴于这个趋势,我和秩鼎(QuantData)的刘相峰和赵爽两位老师合作,利用秩鼎高质量和长跨度的专利数据进行了科技动量的实证分析(专利数据质量对于实证研究至关重要,附录 B 对此进行了介绍)。从上面的介绍可知,构造科技动量的核心是通过专利数据刻画公司之间的相似度;而公司相似度的计算依赖于公司在不同专利主题上的分布。所以,实证的重点就是专利主题的划分。
与 Lee et al. (2019) 和 Bekkerman et al. (2023) 不同,我们最初的构想是借鉴 Bybee et al. (forthcoming) 在新闻数据上使用 LDA 的方法来将专利数据划分为不同的主题,并基于 LDA 主题取代 IPC 分类计算公司的相似度。不过,专利的文本信息有一些自身的特性使得 LDA 的效果并不理想。之后,我们转而使用了 BGE 大语言模型构建语义向量并划分主题,取得了不错的结果。作为对比,我们也仿照 Lee et al. (2019) 使用了 IPC 分类。实证结果表明,无论在全 A 股还是宽基指数成分股,使用 BGE 模型和 IPC 分类并不冲突,二者独立来看都可以获得显著的超额收益,且在控制了彼此之后仍有显著的预测性。
下面就来介绍实证分析中的踩过的坑和重要的发现。让我们先从 LDA 说起。
1 LDA
首先对每个专利的摘要数据分词,之后去除 stop words。接着构建词典,并将分词后的文本转换为文档-词矩阵,使用 LDA 建模。这其中的坑是专利文本有很多特定的专有名词,但它们对于专利的分类并无实质的帮助,例如“装置”、“设备”、“系统”等。下图展示了保留这些特定词汇时,LDA 的分类结果中不同主题的关键词,其中“装置”一词出现在了图中几乎所有主题当中。

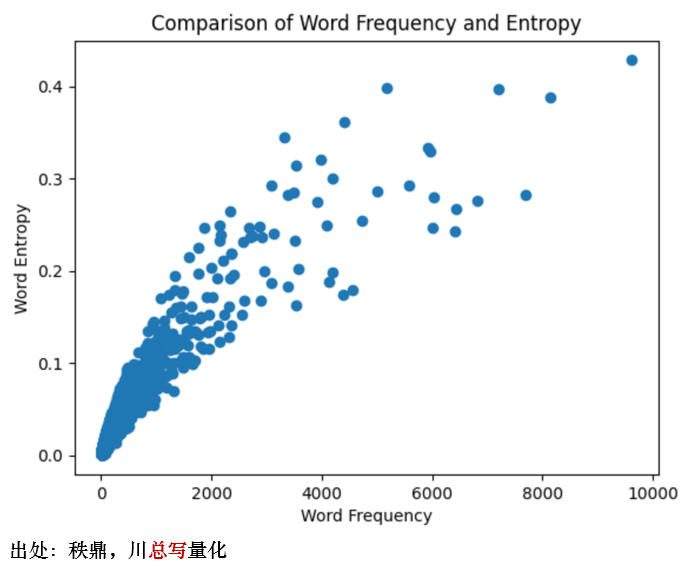
因此,我们需要对这些并没有多少信息含量的特定词汇进行剔除。为了识别它们,最直观的方法是考察词频,此外也可以使用信息熵的方法筛选。这二者的相关性很高(下图)。以信息熵为例,挑选出的词汇包括:设置、技术、结构、系统、利用、领域、表面、设备、产生、特征、步骤、过程、部分、材料、生产、工艺、数据等。
排除特定词汇后,再次利用 LDA 建模,得到不同主题的关键词更加合理。例如:

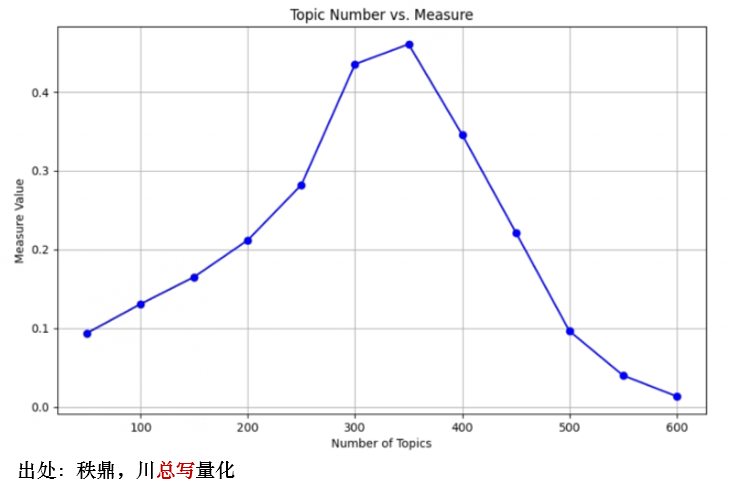
在使用信息熵去除了 500 个特定词汇之后,利用 Jensen–Shannon divergence(JS 散度)确定最优的主题个数。JS 散度是一个对称的 measure,常用于比较两个概率分布的相似性。在 LDA 模型中,我们计算不同主题中词分布的 JS 散度,并使用平均散度衡量不同主题的整体差异程度,其取值越高,说明主题之间的差异越大。下图结果表明,当主题个数在 350 个左右时,平均区分度最优。
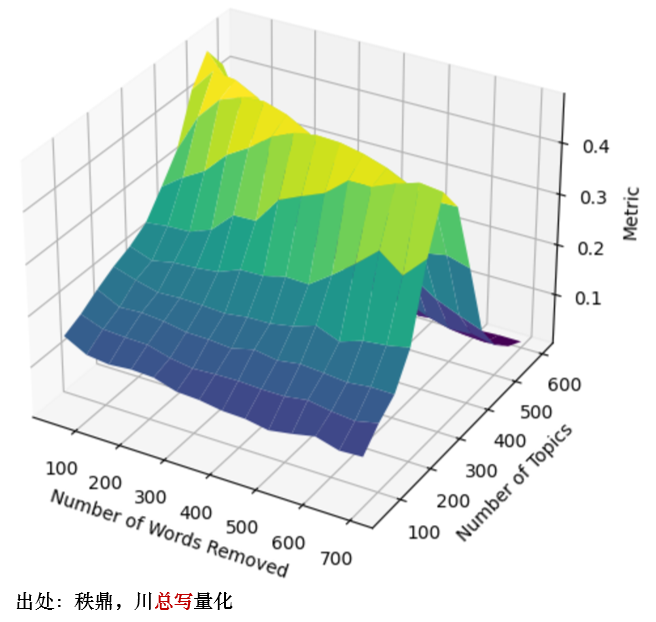
值得一提的是,上述结果是剔除了 500 个特有词汇之后的结果。为了考察结果的稳健性,进一步查看剔除不同个数的特有词汇和最优主题个数的关系(下图)。结果表明,随着剔除的词的增多,最优主题个数从 500 下降至 300 左右。这个结果在一定程度上是合理的,因为剔除的特定词汇越多,剩下的词越有代表性,因此不需要得到更多的主题,就能发挥区分作用。作为对比,如果使用 IPC subclass 分类,那么在 A 股上的主题个数为 584 个,在量级上和 300 到 500 相当(官方当前版本 IPC subclass 类别数量为 651)。
似乎到目前为止,LDA 这条技术路线还是 OK 的。但上述处理完全是基于文本分析的统计处理,没有引入任何先验信息。为了验证 LDA 是否靠谱,下面引入先验信息 —— 使用 IPC 的 subclass 作为主题的 benchmark —— 来考察 LDA 的分类结果。
具体而言,我们的分析目标如下:基于 LDA 和 IPC 主题都可以给每个专利分类;基于分类计算专利之间的相似度。之后,对于每个专利,找出两个方法得到的和其相似度最高的 个专利,然后计算这两个集合之间的 Jaccard 相似度。结果显示,对于绝大多数专利而言,Jaccard 相似度都是零,表明基于 LDA 和 IPC 主题而计算的专利相似度差异巨大。所以,尽管 IPC 主题并非“标准答案”,但无论如何 LDA 的结果并没有得到先验信息的支持。有鉴于此,我们转向大语言模型技术路线。
2 BGE
本节介绍如何使用大语言模型对专利摘要文本构建语义向量,进而进行专利分类。
实证中选择了智源研究院发布的 BGE(BAAI General Embedding)通用语义向量模型 bge-large-zh-v1.5。选择该模型的原因如下:该模型为语义向量模型,区别于词向量模型,不仅考虑词汇信息,而且考虑词汇在文本中的位置,对文本理解更为精准和合理。此外,该模型在中英文语义检索精度与整体语义表征能力均超越了社区所有同类模型,如 OpenAI 的 text embedding 002 等。最后,BGE 保持了同等参数量级模型中的最小向量维度,使用成本更低。
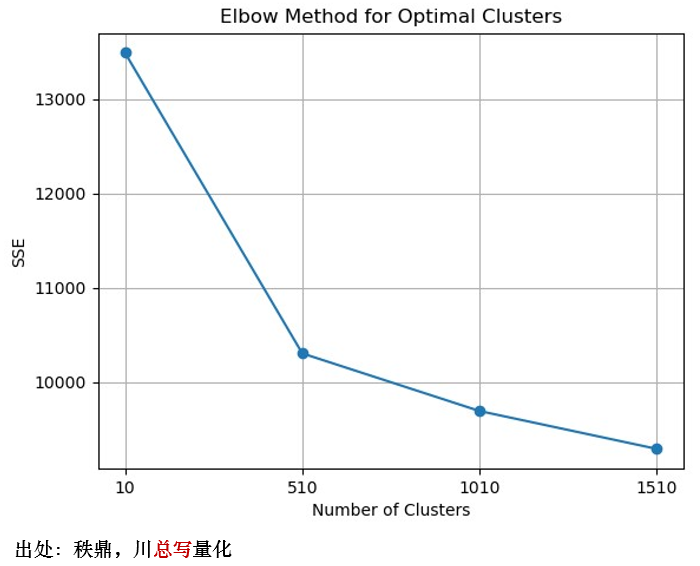
利用该模型,我们对专利摘要文本进行处理,构建 1024 维语义向量。由于当前模型只能处理小于等于 520 个字的文本内容,因此超过的部分会被截掉。由于专利摘要内容通常在 500 字以内,因此该处理不会造成实质性损失。在得到语义向量之后,对它们进行 K-means 聚类分析,得到最后的专利主题。其中,最优的主题数 N 用肘部法则计算得出。实证结果显示, N=500 维时有明显肘部效应(如下图)。这个结果和 LDA 的最优主题个数相一致。
作为 double check,我们依然使用 IPC 作为先验信息,比较了 BGE 和 IPC 两种方法。结果表明,BGE 的分类结果和 IPC 的匹配程度远远高于 LDA,从侧面印证了 BGE 比 LDA 更适用于我们的研究目标。
另外需要说明的是,考虑到整体专利数量超过 600 万条,数据量极大;且专利本身处于持续新增状态,因此整体来看不适合整体进行聚类。因此实证中随机抽取了 10 万条为样本,并基于该样本进行聚类,然后将其他专利和后续新增专利对应到分好的类别中。完成聚类后,共得到 500 个专利主题,然后将每个专利划分到其中一个主题。
最后,由于我们的目标是构造科技动量,因此把专利的分类结果向上聚合到公司层面。为此,考察公司过去一年新增专利,构造 500 维的主题向量。之后,便可以通过比较两两公司之间的专利主题向量的相似性来构造科技动量指标。计算科技动量时,关联公司的历史收益率使用的是过去 1 个月的收益率,与 Lee et al. (2019) 一致。
3 实证结果
为检验科技动量是否有效,每月末依照科技动量取值将股票排序,进行 portfolio sort test。实证区间为 2015 年 3 月到 2024 年 3 月,每月末再平衡。多空投资组合均使用等权加权。下图绘制了全 A 股(在针对全 A 构造多空组合的时候,剔除了市值最低的 20% 股票,以排除壳价值的影响)、中证 500 成分股以及沪深 300 成分股中,科技动量多空组合的累计收益曲线。
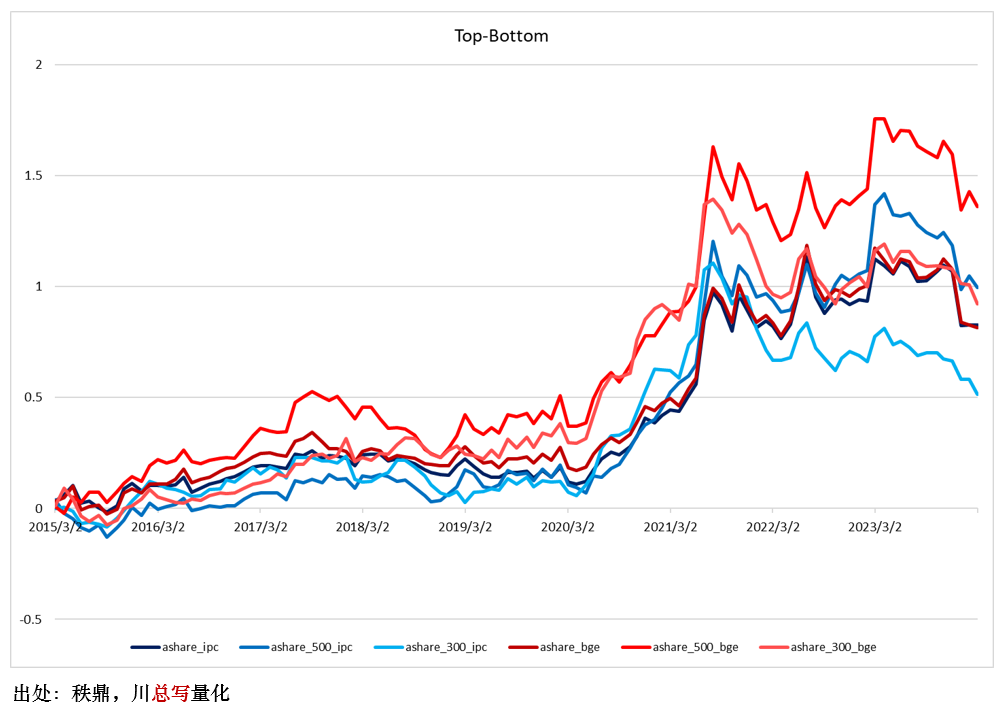
需要说明的是,对于宽基指数成分股而言,实证结果中是依然在全 A 范围内计算焦点公司的关联公司,并计算科技动量。作为稳健性检验,我们也将上述计算仅仅限制在宽基指数成分股之内(但图中并未汇报)。以中证 500 成分股为例,在这种情况下,我们仅仅在 500 的成分股的范围内计算焦点公司的关联公司。结果表明当采用这种方法时,结果也是稳健的。为了和 BGE 对比,实证中还考察了基于 IPC 分类的科技动量。图中结果所示,无论是 BGE 还是 IPC,无论是全 A 还是宽基指数成分股,科技动量的累计超额收益率都呈现上行趋势。
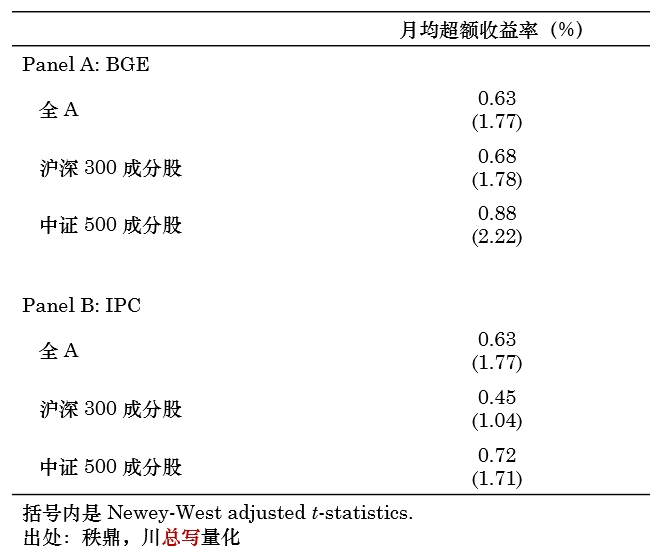
下面进一步通过 time-series regression 检验不同多空组合的月均超额收益率(下表)。结果显示,除了针对沪深 300 使用 IPC 分类之外,其他五个组合的月均超额收益率均在 10% 或 5% 的显著性水平下显著,且基于 BGE 的结果普遍优于基于 IPC 的结果。以中证 500 为例,使用 BGE 构造主题时,科技动量的月均超额收益率为 0.88%,t-statistic 为 2.22。
鉴于上述 portfolio sort 所构造的组合容易受到对其他风格因子暴露的影响,下面进一步使用 Fama-MacBeth regression 考察在控制了常见的 Barra 风格因子之后,使用 BGE 和 IPC 构造的科技动量是否还能够为解释 cross-section 提供增量信息,特别是当同时考察了二者之后的结果又会如何。下表总结了 Fama-MacBeth regression 的 t-statistics。

无论是 Panel A 还是 Panel B,基于 IPC 和 BGE 构造的科技动量因子的 t-statistics 均表明二者包含了关于 cross-section 的信息。其中最重要的结果是,当同时考虑了两者之后,这两种方法构造的因子依然能够为预测股票预期收益率提供增量信息。进一步,考虑到这两个因子的相关系数在 0.57 左右,因此上述结果意味着它们并非替代而是互补的关系。
基于行为金融学的研究表明,“花式动量”的机制和投资者有限注意力以及信息扩散的速度有关。可以想见,基于 IPC 的科技动量计算方法简单直观,因此其所包含的收益率预测信息可能更容易被 priced in(正如 Bekkerman et al. 2023 在美股上针对 Lee et al. 2019 的 comment 一样),而基于 BGE 的构造方法由于数据处理和技术分析的难度更大,因此其信息扩散速度会更加缓慢,因此其所包含的预测信息或许不会很快消失。
本文抛砖引玉,使用 BGE 模型对专利数据进行分类,并检验了 A 股的科技动量效应。相信随着对另类数据的使用越来越深入,专利数据无论是自广度还是深度上,都能够发挥更大的作用。例如,以科技动量为例,我们可以在相似度的基础上结合专利质量得分的信息,通过相似度和质量二者的协同来构造风险调整后收益更优的投资策略。
附录 A IPC
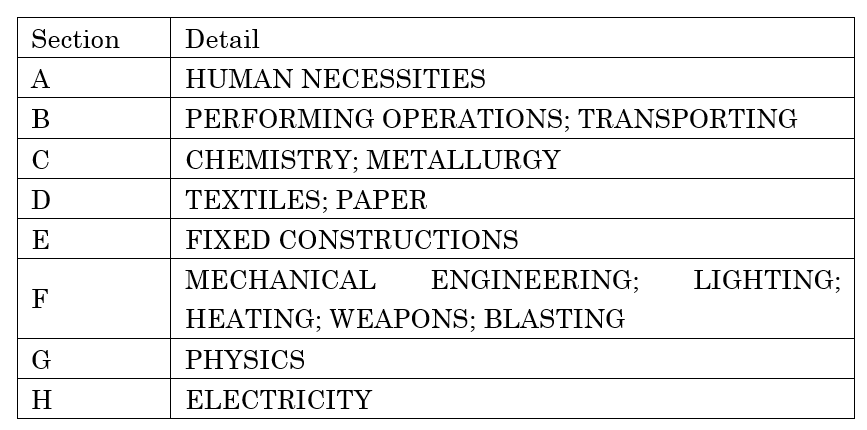
国际专利分类(IPC)由《斯特拉斯堡协定》建立,提供了一种由独立于语言的符号构成的分级系统,用于根据专利和实用新型所涉不同技术领域,对专利和实用新型进行分类。IPC 将技术分为 8 个部类,约七万个复分类。每个复分类都有一个由阿拉伯数字和拉丁字母组成的分类号。
IPC 八个部类:
IPC 号结构说明:
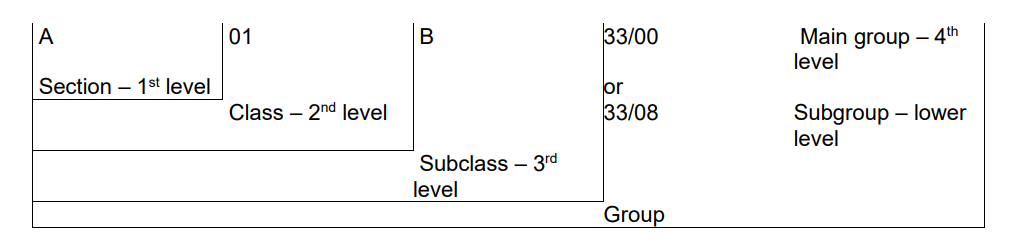
作为科技动量的 benchmark,使用 IPC 的构建方法为:基于每条专利 IPC 号前四位(层级:Subclass),作为专利所属分类,然后以公司过去一年新增专利为基础,构建公司层面的 IPC 向量并计算科技动量。
附录 B 专利数据处理
秩鼎(https://www.quantdata.com.cn/)提供超过 600 万条发明专利数据,涵盖了 A 股 / 港股 / 中概股 / 发债企业 / 其他非上市公司。历史数据可回溯到 1990 年,更新频率为周频。
就专利数据而言,最大的处理难点是股权穿透处理。由于上市公司的专利多数由子公司持有(约 60%),例如百度这样的公司,专利几乎均为子公司持有,因此在上市公司层面,将子公司专利准确对应到母公司(上市公司)上十分重要。秩鼎通过完善的实体公司库和自动化引擎,将国内外上市公司及其子公司的专利归属到母公司。数据处理覆盖了超过 50 万家企业,采用多源数据包括上市公司年报和工商信息,构建了详细的股权关系,包括 1-5 级的股权关联度,以确保专利数据的准确性和历史数据的稳定性。
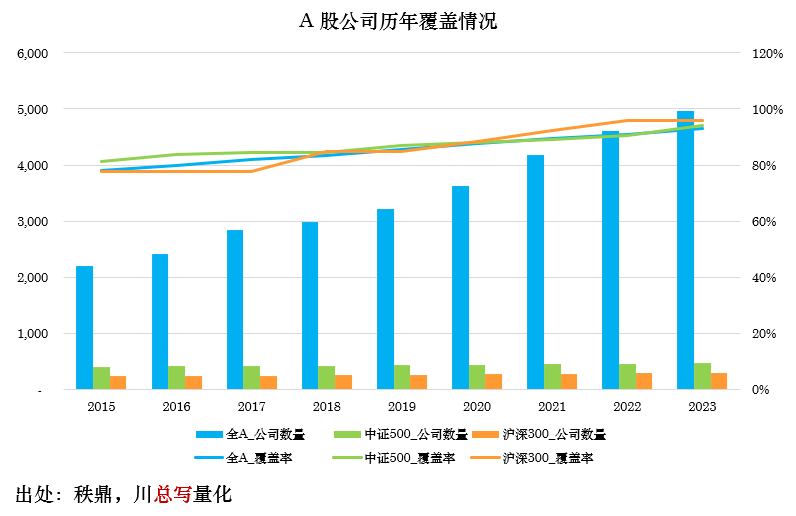
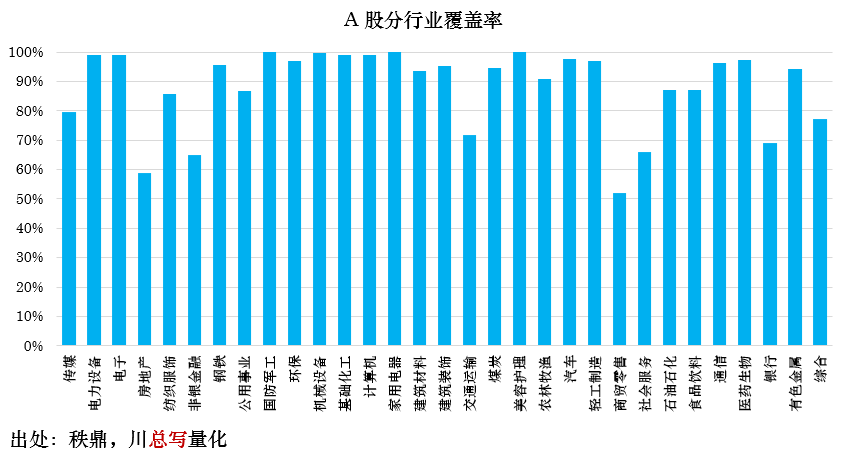
经过以上处理后,专利数据有较好的覆盖率。以下基于每年年末报告期,按 A 股公司及其股权关联度为 1-3 级子公司的专利持有情况进行覆盖率统计;其中行业覆盖率按 2023 年最后一个报告期的情况统计。可见,个股层面覆盖程度逐年提升,行业层面覆盖程度整体保持高位,这些均为实证分析结果的可靠性提供了保障。
参考文献
Bekkerman, R., E. M. Fich, and N. V. Khimich (2023). The effect of innovation similarity on asset prices: Evidence from patents' big data. Review of Asset Pricing Studies 13(1), 99-145.
Bybee, L., B. T. Kelly, A. Manela, and D. Xiu (forthcoming). Business news and business cycles. Journal of Finance.
Lee, C. M. C., S. T. Sun, R. Wang, and R. Zhang (2019). Technological links and predictable returns. Journal of Financial Economics 132(3), 76-96.
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
免责声明:
您在阅读本内容或附件时,即表明您已事先接受以下“免责声明”之所载条款:
1、本文内容源于作者对于所获取数据的研究分析,本网站对这些信息的准确性和完整性不作任何保证,对由于该等问题产生的一切责任,本网站概不承担;阅读与私募基金相关内容前,请确认您符合私募基金合格投资者条件。
2、文件中所提供的信息尽可能保证可靠、准确和完整,但并不保证报告所述信息的准确性和完整性;亦不能作为投资决策的依据,不能作为道义的、责任的和法律的依据或者凭证。
3、对于本文以及文件中所提供信息所导致的任何直接的或者间接的投资盈亏后果不承担任何责任;本文以及文件发送对象仅限持有相关产品的客户使用,未经授权,请勿对该材料复制或传播。侵删!
4、所有阅读并从本文相关链接中下载文件的行为,均视为当事人无异议接受上述免责条款,并主动放弃所有与本文和文件中所有相关人员的一切追诉权。
